# Set the workspace to the current working directory
# Uncomment and replace the path below with your own working directory if needed:
# setwd("/Users/zhaoxiang/Documents/tmp/EC_GLM_notebook")
workspace <- getwd() # Get the current working directory and store it in 'workspace'
# Increase the plot size by adjusting the options for plot dimensions in the notebook output
options(repr.plot.width = 16, repr.plot.height = 8) # Sets width to 16 and height to 8 for larger plots
Single-Species Single-Season Occupancy Model - Practical
Author details: Xiang Zhao, Dr Zachary Amir
Editor details: Dr Zachary Amir
Contact details: support@ecocommons.org.au
Copyright statement: This script is the product of the EcoCommons and WildObs team. Please refer to the EcoCommons website for more details: https://www.ecocommons.org.au/
For more information about WildObs, please visit https://wildobs.org.au and https://github.com/WildObs
Date: Feb 2026
Script information
There are two notebooks about Single-Species Single-Season Occupancy Model, one is conceptual (click here to learn more), and another is practical. This one is the practical notebook which gives a brief introduction to the concepts of Single-Species Single-Season Occupancy Model with some simulated data.
This notebook, developed by the EcoCommons and WildObs team, showcases how to build Single-Species Single-Season Occupancy Model with camera trapping data with “unmarked” R package (click here to learn more).
Other file formats of this notebook
| Notebook | Files | Open in Colab / ARDC Jupyter | DOI |
|---|---|---|---|
| Occupancy - Practical |   |
Introduction
Occupancy models provide a powerful framework for estimating where species occur while accounting for imperfect detection — a common challenge in wildlife research. Camera traps are particularly well suited to this task because they generate repeated detection–non-detection data that can be structured into the hierarchical models implemented in the unmarked R package.
Single-species, single-season abundance models that account for imperfect detection can also be calculated in the unmarked R package using much of the same approach described here, and these models are known as N-Mixture models. The key distinction is that abundance models use count data to estimate a species’ abundance rather than detection–non-detection data. However, the assumptions of N-Mixture models are easily violated and requires careful interpretation (See Link et al., 2018 & Nakashima, 2020 to learn more). This practical notebook demonstrates how to build a single-species, single-season occupancy model using camera-trap data curated and standardised through the Wildlife Observatory of Australia (WildObs) platform. WildObs processes raw camera-trap images using artificial intelligence (e.g., MegaDetector, SpeciesNet, and bespoke regional computer vision models, such as our first model from the Wet Tropics of QLD), employs the CamtrapDP data standard, and provides harmonised tables describing deployments, observations, media, and range of spatial and temporal covariates that are ready for ecological analysis.
Wildlife Observatory of Australia

Wildlife Observatory of Australia - Australia’s national platform for processing and sharing wildlife camera data. WildObs will transform how Australia handles wildlife camera data by creating a national platform powered by AI. It will streamline biodiversity monitoring, break down data silos, and support effective conservation strategies by providing researchers and policymakers with easy access to consistent, high-quality data for informed decision-making. The WildObs researcher network is supported by Australia’s National Research Infrastructure. TERN supports the field observatory and standard protocols, ALA hosts the tagged image repository and ARDC Planet Research Data Commons, through QCIF, is building a user-friendly data management and access platform.
For more information about WildObs, please visit https://wildobs.org.au and https://github.com/WildObs
WildObsR R package
![]()
![]()
![]()
Professional tools for camera trap data access, management, and analysis in R
WildObsR provides a comprehensive suite of functions for processing, standardizing, and analyzing wildlife camera trap data. Built to support the Camera Trap Data Package (camtrap DP) data standard and Frictionless Data specifications, this package streamlines workflows from raw observations to publication-ready analyses. Camtrap DP is a is a community-developed data exchange format for camera trap data, which enhances interoperability with other R packages and functions, such as with the camtrapdp R package, camtraptor R package, and camtrapR R package.
For more information of this R package, please visit https://github.com/WildObs/WildObsR
Objectives
Install WildObsR R package
Download and inspect WildObs camera-trap projects using
WildObsR::wildobs_mongo_query()&WildObsR::wildobs_dp_download()Inspect and prepare site-level and observation-level covariates
Spatially resample deployments & covariates into biologically meaningful sampling units using
WildObsR::spatial_hexagon_generator()&WildObsR::resample_covariates_and_observations()Construct detection history matrices using
WildObsR::matrix_generator()Build the unmarkedFrameOccu (UMF) object using
unmarked::unmarkedFrameOccuFit occupancy models using
unmarked::occu(), compare competing models to determine the top model, and then visualize & interpret the results
Workflow Overview
| Notebooks | Main Content | Sub-content |
|---|---|---|
Single-Species Single-Season Occupancy Model - Conceptual visit here to see |
Overview and Conceptualisation | 1.1 What is Occupancy modelling? 1.2 Single-species, single-season occupancy model and assumptions 1.3 Single-species, single-season occupancy model with covariates |
| Single-Species Single-Season Occupancy Model - Practical (this notebook) | Occupancy model with camera traps | 1.1 Camera Trap 1.2 Camera trap surveys in Queensland’s Wet Tropics 2022-2023 1.3 How to prepare camera trap data for occupancy model 1.4 Occupancy model with WildObs data |
In the near future, this material may form part of comprehensive support materials available to EcoCommons users. If you have any corrections or suggestions to improve the efficiency, please contact the EcoCommons team.

Set-up: R Environment and Packages
Some housekeeping before we start. This process might take some time as many packages needed to be installed.
S.1 Set the working directory and create a folder for data.
Save the Quarto Markdown file (.QMD) to a folder of your choice, and then set the path to your folder as your working directory.
S.2 Install and load essential libraries.
Install and load R packages.
# Set CRAN mirror
options(repos = c(CRAN = "https://cran.rstudio.com/"))
## load libs
# WildObsR for accessing WildObs data and bespoke data wrangling function
# frictionless for working with frictionless data packages and extracting data resources
# unmarked for running frequentist occupancy and/or abundance models
# Required packages
packages <- c("unmarked", "ggplot2", "plyr", "dplyr", "frictionless", "tidyverse", "janitor", "knitr", "leaflet", "htmltools", "MuMIn")
# Install any missing packages
for (pkg in packages) {
if (!requireNamespace(pkg, quietly = TRUE)) {
install.packages(pkg)
}
library(pkg, character.only = TRUE)
}S.3 WildObsR R package
![]()
![]()
![]()
WildObs stores all spreadsheets of camera trap data in a remote MongoDB database, which enables remote downloads of both new and legacy camera trap data ready for analysis. This is achieved through two key functions: WildObsR::wildobs_mongo_query() & WildObsR::wildobs_dp_download().
- The first function (
WildObsR::wildobs_mongo_query()) allows you to query the WildObs database for camera trap projects matching specific spatial, temporal, taxonomic, contributor, sampling design, and/or data-sharing criteria. This function produces a vector of camera trap projectIDs that are available for download using the second function. - The second function (
WildObsR::wildobs_dp_download()) is a data package download function that connects to the WildObs MongoDB server, retrieves project-specific metadata and data resources, and bundles them into Frictionless Data Packages formatted using the camtrap DP data standard.
As WildObs continues to update their MongoDB database with new data, re-running the same query may provide additional camera trap data projects through time. However, WildObsR’s other functionality (e.g., WildObsR::matrix_generator()) is frequently updated. Thereofre, please use the below function to keep your WildObsR R package the most updated version.
# Install WildObsR from GitHub (WildObs/WildObsR)
# This installer avoids GitHub tokens by installing directly from a public tarball.
# It is suitable for workshops, teaching notebooks, and CI environments.
install_or_update_WildObsR <- function(ref = "main") {
if (!requireNamespace("WildObsR", quietly = TRUE)) {
message("WildObsR not found. Installing from GitHub...")
install.packages(
sprintf(
"https://github.com/WildObs/WildObsR/archive/refs/heads/%s.tar.gz",
ref
),
repos = NULL,
type = "source"
)
message("WildObsR installed successfully.")
} else {
message("WildObsR is already installed. Skipping installation.")
}
invisible(TRUE)
}
# Run the install process
install_or_update_WildObsR()WildObsR is already installed. Skipping installation.# Note:
# - This installation method does not require a GitHub Personal Access Token.
# - Installation time depends on your R environment and which dependencies
# are already installed. The first installation may take longer.1 Occupancy model with camera traps
1.1 Camera Traps
Camera traps are widley used in wildlife research and monitoring due to their logistical advantages such as low labour intensity, low cost, and long temporol coverage. As a result, camera trap survey are increasingly generating high resolution data sets spanning individual regions (Anderson et al., 2025) to entire continents (Bruce et al., 2025).
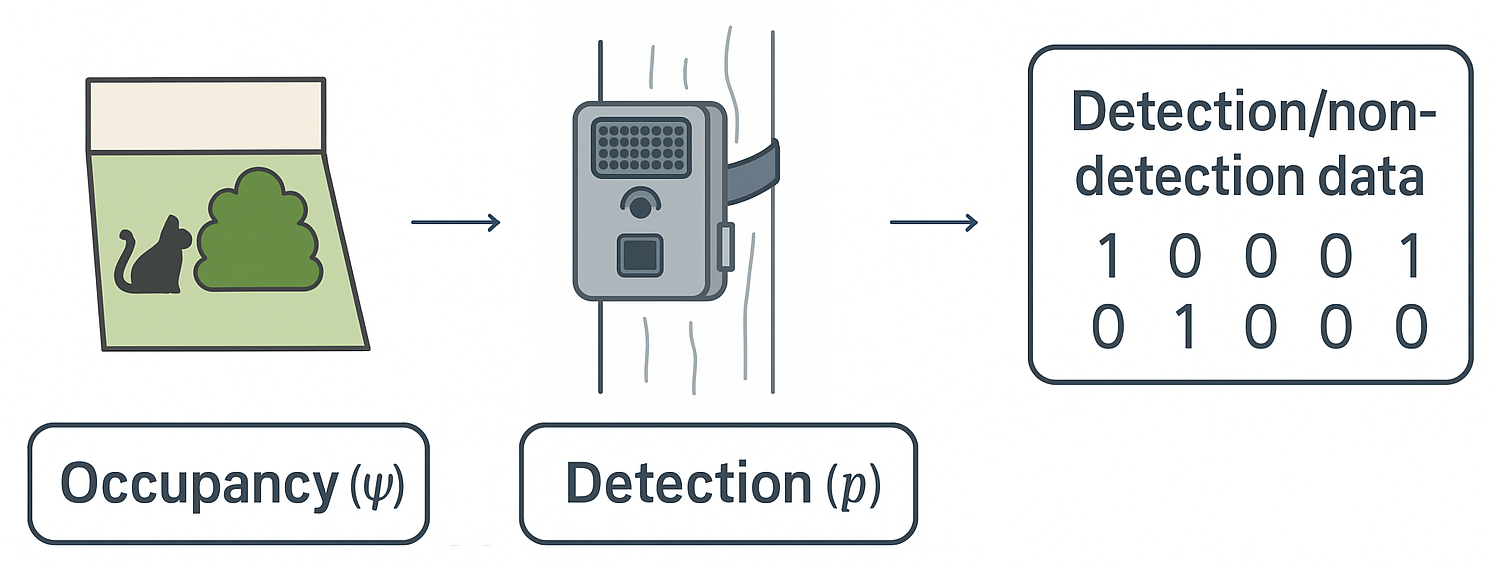
Figure 1. Key components of occupancy modelling with camera trap. A species may be present at a site (occupancy, ψ), but detection is imperfect. Camera traps provide repeated detection events, producing detection/non-detection histories that allow estimation of both occupancy (ψ) and detection probability (p).
1.2 Camera trap surveys in Queensland’s Wet Tropics 2022-2023
This data was collected by Dr Zachary Amir and the Ecological Cascades Lab at the University of Queensland to study interactions between native and invasive vertebrates in North Queensland’s Wet Tropics Rainforests. The camera trap surveys conducted here complement and extend prior surveys conducted by Dr. Tom Bruce as part of his PhD research studying feral cats in North Queensland forests. Important to note that these surveys implemented paired camera deployments, where each sampling location received a camera placed on the road and another camera placed 50 m into the bush. Sampling locations were typically spaced 1km apart from each other, though this varies between small and large landscapes.
This dataset has been published with the Atlas of Living Australia (ALA) through the CamtrapDP data exchange format https://camtrap-dp.tdwg.org/) and transformed into a Darwin Core dataset. You can access the occurrence records from this dataset here and you can access a curated selection of camera trap images from this survey hosted on the ALA here.
1.3 How to prepare camera trap data for occupancy models
WildObs is developing an online Wildlife Image Management Platform powered by Agouti to enable researchers to use computer vision AI models to rapidly convert camera trap media (i.e., images and/or videos) into spreadsheets. These spreadsheets are standardized and harmonized by WildObs and incorporated into WildObs’s database and accessible via the WildObsR package. The WildObs image managment platform is still in development, but if you are interested in being an early tester or receiving updates about WildObs’s development, please complete this form to be added to the WildObs contact list.
Here we just give a brief the summary points of what we had done:
1.3.1 Query WildObs MongoDB for Relevant Project IDs and Download Projects
Step 1: All raw camera trapped images have had their wildlife classified by humans or with computer vision models including detection models like MegaDetector and classifiers like SpeciesNet, to generate species identifications. The images generated in this data were classified by the Wildlife Insights’s SpeciesNet computer vision model and identifications were manually verified and corrected if necessary by humans.
We will access the relevant camera trap project we want using the two functions WildObsR::wildobs_mongo_query() & WildObsR::wildobs_dp_download().
WildObsR::wildobs_mongo_query function
This function queries the WildObs MongoDB database for projects matching specified spatial, temporal, taxonomic, contributor, and data-sharing criteria. It extracts metadata from the database and filters projects based on bounding box overlaps, temporal overlaps, species detected, contributors associated, matched sampling designs, and data sharing preferences. The function also ensures that only projects that have past their embargo date are shared.
# Load libraries
library(WildObsR)
library(frictionless) ## For working with data packages
# Use general API key
api_key <- "f4b9126e87c44da98c0d1e29a671bb4ff39adcc65c8b92a0e7f4317a2b95de83"
# Query projects in Queensland from 2020-2024
spatial_query <- list(xmin = 145.0, xmax = 154.0, ymin = -29.0, ymax = -10.0)
temporal_query <- list(minDate = as.Date("2020-01-01"),
maxDate = as.Date("2024-12-31"))
# run the query
project_ids <- wildobs_mongo_query(
api_key = api_key,
spatial = spatial_query,
temporal = temporal_query,
tabularSharingPreference = c("open", "partial")
)
project_ids [1] "QLD_Kgari_BIOL2015_2023-24_WildObsID_0004"
[2] "QLD_Paluma_cassowary_Mclean_2023-24_WildObsID_0006"
[3] "ZAmir_QLD_Wet_Tropics_2022_WildObsID_0001"
[4] "QLD_Dwyers_Scrub_ANIM3018_2023_WildObsID_0005"
[5] "QLD_Kgari_potoroos_Amir_2022_WildObsID_0003" ZAmir_QLD_Wet_Tropics_2022_WildObsID_0001
Out of the 5 projects listed above, we are going to use “ZAmir_QLD_Wet_Tropics_2022_WildObsID_0001” for this notebook.
WildObsR::wildobs_dp_download()
This function connects to the WildObs MongoDB server, retrieves project-specific metadata and data resources, and bundles them into Frictionless Data Packages formatted using the camtrap DP data standard. Note, while neither the db_url or api_key parameters are required, the function will return an error if at least one of these parameters are not provided.
project_ids <- project_ids[project_ids == "ZAmir_QLD_Wet_Tropics_2022_WildObsID_0001"]
# Download data packages
dp_list <- wildobs_dp_download(
api_key = api_key,
project_ids = project_ids,
media = FALSE, # We don't need media files for this notebook, and they are slow to download
metadata_only = FALSE
)dp_list is list object containing the single data package specified in project_ids, though it could contain multiple projects. The data packages are formated in camtrap DP.
class(dp_list)[1] "list"class(dp_list[[1]])[1] "camtrapdp" "datapackage" "list" dp_list[[1]]A Data Package with 3 resources:
• deployments
• observations
• covariates
Use `unclass()` to print the Data Package as a list.As you can see, the dp_list is a list class, while dp_list[[1]] is a camtrapdp datapackage class.
| Object | Meaning | What you get |
|---|---|---|
| dp_list | A list of all downloaded data packages | A list with 1+ elements |
| dp_list[[1]] | The first actual data package inside the list. Since there is only one project (‘ZAmir_QLD_Wet_Tropics_2022_WildObsID_0001’), dp_list[[1]] corresponds to that package. | A camtrapdp datapackage object with 3 resources:
|
1.3.2 Resources extract
Step 2: Just like in our data simulation in Single-Species Single-Season Occupancy Model - Conceptual, we must extract and inspect the three resources:
site-level covariates → found in the covariates & deployments data resources, which can easily be merged together by shared columns.
observation-level covariates → found in the observations data resources (i.e., must vary with time)
detection-history matrix → generated from the detection events of the observations data resource
# Create storage lists
covariates_list <- list()
deployments_list <- list()
observations_list <- list()
for (i in seq_along(dp_list)) {
dp <- dp_list[[i]] # in case we have more than one project id in the dp_list, although we are only going to use one, "ZAmir_QLD_Wet_Tropics_2022_WildObsID_0001"
# Extract the principal investigator's name (abbreviated) to ensure multiple sources can be bound together
pi_tag <- dp$contributors %>%
# select the pi
purrr::keep(~ .x$role == "principalInvestigator") %>%
# grab the title
purrr::pluck(1, "title") %>%
{
# take the first letter of the first name
parts <- strsplit(., " ")[[1]]
# and bind w/ the second
paste0(substr(parts[1], 1, 1), "_", parts[length(parts)])
}
## ---- DEPLOYMENTS ----
deployments_i <- frictionless::read_resource(dp, "deployments")
deployments_i$source <- pi_tag
deployments_list[[i]] <- deployments_i
## ---- COVARIATES ----
covariates_i <- frictionless::read_resource(dp, "covariates")
covariates_i$source <- pi_tag
covariates_list[[i]] <- covariates_i
## ---- OBSERVATIONS ----
observations_i <- frictionless::read_resource(dp, "observations")
observations_i$source <- pi_tag
observations_list[[i]] <- observations_i
}
# Now bind them into full data frames
deployments <- do.call(rbind, deployments_list)
covariates <- do.call(rbind, covariates_list)
observations <- do.call(rbind, observations_list)
# Clean up
rm(covariates_i, deployments_i, observations_i, dp, i, pi_tag)Let’s have a look on the three data frames we just created.
Deployments of ZAmir_QLD_Wet_Tropics_2022_WildObsID_0001
print(head(deployments))# A tibble: 6 × 27
deploymentID locationID locationName latitude longitude coordinateUncertainty
<chr> <chr> <chr> <dbl> <dbl> <int>
1 WOONP_01_2022 WOONP_01 Wooroonoora… -17.3 146. 1
2 WOONP_02_202… WOONP_02 Wooroonoora… -17.3 146. 1
3 WOONP_02_202… WOONP_02 Wooroonoora… -17.3 146. 1
4 WOONP_03_202… WOONP_03 Wooroonoora… -17.3 146. 1
5 WOONP_03_202… WOONP_03 Wooroonoora… -17.3 146. 1
6 WOONP_04_202… WOONP_04 Wooroonoora… -17.3 146. 1
# ℹ 21 more variables: deploymentStart <dttm>, deploymentEnd <dttm>,
# setupBy <chr>, cameraID <chr>, cameraModel <chr>, cameraDelay <int>,
# cameraHeight <dbl>, cameraDepth <dbl>, cameraTilt <int>,
# cameraHeading <int>, detectionDistance <dbl>, timestampIssues <lgl>,
# baitUse <lgl>, featureType <fct>, habitat <chr>, deploymentGroups <chr>,
# deploymentTags <chr>, deploymentComments <chr>,
# multiSeason_deploymentGroup <chr>, projectName <chr>, source <chr>The deployments table contains contextual data for each camera deployment, including the deployment ID, site information (location ID, name, coordinates, uncertainty), deployment period, camera specifications (model, height, delay, tilt, heading), environmental context (feature type, habitat), and project-level annotations such as tags, groups, and comments. The first several rows shown above illustrate typical entries from the Wooroonooran NP project in 2022–2023.
Observations of ZAmir_QLD_Wet_Tropics_2022_WildObsID_0001
print(head(observations))# A tibble: 6 × 37
observationID deploymentID mediaID eventID eventStart
<chr> <chr> <chr> <chr> <dttm>
1 CFRAG_01_bush_20221215_Z_Ami… CFRAG_01_20… CFRAG_… CFRAG_… 2022-12-19 08:04:09
2 CFRAG_01_bush_20221215_Z_Ami… CFRAG_01_20… CFRAG_… CFRAG_… 2023-01-08 08:13:25
3 CFRAG_01_bush_20221215_Z_Ami… CFRAG_01_20… CFRAG_… CFRAG_… 2023-01-08 07:29:04
4 CFRAG_01_bush_20221215_Z_Ami… CFRAG_01_20… CFRAG_… CFRAG_… 2023-01-08 08:13:03
5 CFRAG_01_bush_20221215_Z_Ami… CFRAG_01_20… CFRAG_… CFRAG_… 2023-01-08 09:26:03
6 CFRAG_01_bush_20221215_Z_Ami… CFRAG_01_20… CFRAG_… CFRAG_… 2023-01-08 10:10:42
# ℹ 32 more variables: eventEnd <dttm>, observationLevel <fct>,
# observationType <fct>, cameraSetupType <fct>, scientificName <chr>,
# count <int>, lifeStage <fct>, sex <fct>, behavior <chr>,
# individualID <chr>, individualPositionRadius <dbl>,
# individualPositionAngle <dbl>, individualSpeed <dbl>, bboxX <dbl>,
# bboxY <dbl>, bboxWidth <dbl>, bboxHeight <dbl>, classificationMethod <fct>,
# classifiedBy <chr>, classificationTimestamp <lgl>, …The observations table contains observation-level records detected by each camera, including timestamps, media identifiers, and links back to their deployment. Each row represents either a blank trigger or an animal detection, with associated metadata such as species identification, life stage, sex, behaviour, bounding-box coordinates, classification method, and timing variables (eventStart, eventEnd). Note that observationID has been calculated to group 5-minute camera triggers together, while eventID groups larger 30-minute detection intervals. The first six rows show a mix of blank events and a detection of Megapodius reinwardt within the CFRAG_01 deployment.
Covariates of ZAmir_QLD_Wet_Tropics_2022_WildObsID_0001
print(head(covariates))# A tibble: 6 × 83
deploymentID locationID locationName latitude longitude deploymentStart
<chr> <chr> <chr> <dbl> <dbl> <dttm>
1 CFRAG_01_2022_… CFRAG_01 Eacham_Curt… -17.3 146. 2022-12-15 08:52:45
2 CFRAG_01_2022_… CFRAG_01 Eacham_Curt… -17.3 146. 2022-12-15 08:19:27
3 CFRAG_02_2022_… CFRAG_02 Eacham_Curt… -17.3 146. 2022-12-15 09:58:36
4 CFRAG_02_2022_… CFRAG_02 Eacham_Curt… -17.3 146. 2022-12-15 09:40:56
5 CFRAG_03_2022_… CFRAG_03 Eacham_Curt… -17.3 146. 2022-12-15 11:00:58
6 CFRAG_03_2022_… CFRAG_03 Eacham_Curt… -17.3 146. 2022-12-15 10:36:47
# ℹ 77 more variables: deploymentEnd <dttm>, deploymentGroups <chr>,
# FLII_point <dbl>, FLII_1km2 <dbl>, FLII_3km2 <dbl>, FLII_5km2 <dbl>,
# FLII_10km2 <dbl>, human_footprint_point <dbl>, human_footprint_1km2 <dbl>,
# human_footprint_3km2 <dbl>, human_footprint_5km2 <dbl>,
# human_footprint_10km2 <dbl>, altitude_point <dbl>, altitude_1km2 <dbl>,
# altitude_3km2 <dbl>, altitude_5km2 <dbl>, altitude_10km2 <dbl>,
# ecoregion_intactness_point <dbl>, ecoregion_intactness_1km2 <dbl>, …The covariates table provides spatio-temporal environmental and landscape attributes associated with each camera deployment. It includes spatial location (latitude/longitude), deployment period, and group labels, along with a wide range of ecological covariates summarised at multiple spatial scales (point, 1 km², 3 km², 5 km², 10 km²). These covariates capture habitat condition (e.g., Forest Landscape Integrity Index (FLII)), human pressure (human footprint index), topography (altitude), climate variables (temperature, precipitation), vegetation indices (NDVI), nighttime lights, and other environmental descriptors. The first several rows show covariate profiles for the CFRAG deployments in the Lake Eacham–Curtain Fig deploymentGroup
All frictionless data packages contain schemas that describes each column in each table, providing useful additional context for unknown data fields. These can be accessed through the function frictionless::get_schema(). This is particularly useful for the covariates table due to the large number of available covariates, which provides information about how each covariate was calculated. We can easily convert the schema to a table for easier viewing and manipulation, but will inspect schemas for other data resources later.
# extract schema
covs_schema = frictionless::get_schema(dp_list[[1]], "covariates")
# convert to a df
fields_df <- do.call(
# bind each row
rbind,
# and extract value from schema fields for
lapply(covs_schema$fields, function(f) {
data.frame(
# col name,
name = f$name %||% NA_character_,
# and description
description = f$description %||% NA_character_,
stringsAsFactors = FALSE
)
})
)For example, we can view the description of the NDVI variable calculated per camera trap: Mean NDVI (Normalized Difference Vegetation Index) extracted from a 1 km resolution raster layer representing vegetation density across Australia. NDVI reflects vegetation greenness and health and is widely used in ecological and land surface monitoring. The raster stores a focal mean of NDVI calculated using a 5km circular window, derived from the National Forest and Sparse Woody Vegetation dataset (2021). This variable has been calculated with a 1 meter buffer around each deploymentID.
1.3.3 Mapping camera sites
Before we dive into the data, let’s take a moment to map out all the sites where teams worked tirelessly to deploy cameras and collect these images. Their efforts deserve recognition
# Clean columns
cov <- covariates |> clean_names()
# Filter usable rows
mpts <- cov |> filter(!is.na(latitude), !is.na(longitude))
# Count cameras per site (force dplyr version)
site_counts <- dplyr::count(mpts, location_name)
# Old dplyr rename syntax: rename(OLD = NEW)
site_counts <- dplyr::rename(site_counts, n_cameras = n)
# Create "Site (N)" labels
site_labels <- setNames(
paste0(site_counts$location_name, " (", site_counts$n_cameras, ")"),
site_counts$location_name
)
# Add a labelled version to the data
mpts <- mpts |>
mutate(location_label = site_labels[location_name])
# Colour palette
pal <- colorFactor("Set2", domain = unique(mpts$location_name))
# Popup builder
popup_html <- function(df) {
paste0(
"<b>Deployment:</b> ", htmlEscape(df$deployment_id), "<br/>",
"<b>LocationID:</b> ", htmlEscape(df$location_id), "<br/>",
"<b>Landscape:</b> ", htmlEscape(df$location_name), "<br/>",
"<b>Start:</b> ", htmlEscape(as.character(df$deployment_start)), "<br/>",
"<b>End:</b> ", htmlEscape(df$deployment_end), "<br/>",
"<b>Altitude (m):</b> ", df$altitude_point, "<br/>",
"<b>NDVI:</b> ", round(df$ndvi_point, 3)
)
}
# Precompute popups
popups <- popup_html(mpts)
# Map extent
lat_rng <- range(mpts$latitude, na.rm = TRUE)
lon_rng <- range(mpts$longitude, na.rm = TRUE)
# Leaflet map
leaflet(mpts) %>%
addProviderTiles("CartoDB.Positron", group = "Light") %>%
addProviderTiles("Esri.WorldImagery", group = "Satellite") %>%
addScaleBar(position = "bottomleft") %>%
addCircleMarkers(
lng = ~longitude, lat = ~latitude,
radius = 6, stroke = TRUE, weight = 1, opacity = 1,
color = ~pal(location_name), fillOpacity = 0.85,
label = ~location_label,
popup = popups,
clusterOptions = markerClusterOptions(removeOutsideVisibleBounds = TRUE),
group = "Deployments"
) %>%
addLegend(
"topright",
pal = pal,
values = ~location_name,
labFormat = labelFormat(
transform = function(values) site_labels[values]
),
title = "Landscape (Camera Count)",
opacity = 1
) %>%
addLayersControl(
baseGroups = c("Light", "Satellite"),
overlayGroups = c("Deployments"),
options = layersControlOptions(collapsed = FALSE)
) %>%
fitBounds(
lon_rng[1], lat_rng[1],
lon_rng[2], lat_rng[2]
)In the above interactive map, you can see the location of each camera.
Camera sites description, adapted from Anderson et al. (2025)
|
Sites |
Forest size (km2) |
Elevation (m) |
Monthly rainfall (mm) |
Forest integrity |
Human footprint |
Cams |
Trap nights |
Start date |
End data |
|---|---|---|---|---|---|---|---|---|---|
|
Daintree National Park |
1200 |
61 |
253 |
7.7 |
22.2 |
44 |
2666 |
2022-09-20 |
2022-12-07 |
|
Danbulla National Park |
120 |
755 |
124 |
7 |
2 |
41 |
2520 |
2022-10-04 |
2023-01-05 |
|
Eacham Curtain Fig National Park |
11.6 |
745 |
146 |
1.2 |
10.5 |
32 |
1826 |
2022-12-15 |
2023-03-07 |
|
Mount Lewis National Park |
278.6 |
986 |
140 |
9.8 |
0.1 |
44 |
2640 |
2022-09-27 |
2022-12-15 |
|
Wooroonooran Goldfiled Track |
361 |
180 |
289 |
8.6 |
2 |
48 |
3223 |
2022-12-12 |
2023-03-17 |
|
Wooroonooran National Park Core |
798 |
648 |
252 |
7.8 |
3.6 |
66 |
4203 |
2022-12-20 |
2023-03-19 |
vars_box <- c("FLII_point", "altitude_point", "NDVI_point", "human_footprint_point")
covs_long <- covariates %>%
tidyr::pivot_longer(
all_of(vars_box),
names_to = "variable",
values_to = "value"
) %>%
dplyr::mutate(
variable = factor(
variable,
levels = vars_box,
labels = c(
"Forest Landscape Integrity Index (point)",
"Altitude (m)",
"NDVI (point)",
"Human Footprint (point)"
)
)
)
ggplot(covs_long, aes(x = locationName, y = value, fill = locationName)) +
geom_boxplot(outlier.alpha = 0.3) +
facet_wrap(~ variable, scales = "free_y", ncol = 2) +
labs(
x = "Site (locationName)",
y = NULL,
title = "Covariate distributions by landscape"
) +
theme_minimal(base_size = 12) +
theme(
axis.text.x = element_text(angle = 30, hjust = 1),
legend.position = "none" # optional — remove legend if cluttered
)
Mount_Lewis_NP and Wooroonooran_Goldfield_Track are high-elevation, high-integrity rainforest sites with very high NDVI.
Daintree_NP and Danbulla_NP are lower-elevation but still high-integrity.
Eacham_Curtain_Fig_NPs stands out as the only disturbed site — very low FLII, low NDVI, and the highest human footprint.
1.3.4 WildObs Data Integrity Check & Pre-processing
This block performs data inspection, schema extraction, validation, and pre-processing for the three WildObs resources: deployments, observations, and covariates.
# Define a helper function to summarise a dataset
dataset_summary <- function(df, name) {
# Create a small tibble containing basic metadata about the dataset
tibble(
dataset = name, # Name of the dataset (e.g. "observations")
n_rows = nrow(df), # Total number of rows in the data frame
n_cols = ncol(df) # Total number of columns in the data frame
)
}
# Combine summary information for each dataset into a single table
bind_rows(
dataset_summary(observations, "observations"), # Summary of observations table
dataset_summary(deployments, "deployments"), # Summary of deployments table
dataset_summary(covariates, "covariates") # Summary of covariates table
) %>%
print() # Print the combined summary table to the console# A tibble: 3 × 3
dataset n_rows n_cols
<chr> <int> <int>
1 observations 130682 37
2 deployments 275 27
3 covariates 275 83From the summary above, the observations, deployments, and covariates datasets contain 37, 27, and 83 fields, respectively. Although the deployments and covariates tables contain 27 and 83 fields respectively, not all fields are shared between them. To better understand their structural relationship, we compared the column names to identify common fields and those unique to each table.
# Identify column names that are shared between deployments and covariates
# These fields are typically used as identifiers or join keys
intersect(names(deployments), names(covariates)) %>%
sort() %>% # Sort alphabetically for readability
kable(
col.names = "Common Fields",
caption = "Fields Present in Both Deployments & Covariates"
)| Common Fields |
|---|
| deploymentEnd |
| deploymentGroups |
| deploymentID |
| deploymentStart |
| latitude |
| locationID |
| locationName |
| longitude |
| projectName |
| source |
# Identify fields that exist only in the deployments table
# These describe deployment-specific metadata
setdiff(names(deployments), names(covariates)) %>%
kable(col.names = "Only in Deployments")| Only in Deployments |
|---|
| coordinateUncertainty |
| setupBy |
| cameraID |
| cameraModel |
| cameraDelay |
| cameraHeight |
| cameraDepth |
| cameraTilt |
| cameraHeading |
| detectionDistance |
| timestampIssues |
| baitUse |
| featureType |
| habitat |
| deploymentTags |
| deploymentComments |
| multiSeason_deploymentGroup |
# Identify fields that exist only in the covariates table
# These are typically environmental or derived variables
setdiff(names(covariates), names(deployments)) %>%
kable(col.names = "Only in Covariates")| Only in Covariates |
|---|
| FLII_point |
| FLII_1km2 |
| FLII_3km2 |
| FLII_5km2 |
| FLII_10km2 |
| human_footprint_point |
| human_footprint_1km2 |
| human_footprint_3km2 |
| human_footprint_5km2 |
| human_footprint_10km2 |
| altitude_point |
| altitude_1km2 |
| altitude_3km2 |
| altitude_5km2 |
| altitude_10km2 |
| ecoregion_intactness_point |
| ecoregion_intactness_1km2 |
| ecoregion_intactness_3km2 |
| ecoregion_intactness_5km2 |
| ecoregion_intactness_10km2 |
| mean_monthly_precipitation_point |
| mean_monthly_precipitation_1km2 |
| mean_monthly_precipitation_3km2 |
| mean_monthly_precipitation_5km2 |
| mean_monthly_precipitation_10km2 |
| mean_monthly_temperature_point |
| mean_monthly_temperature_1km2 |
| mean_monthly_temperature_3km2 |
| mean_monthly_temperature_5km2 |
| mean_monthly_temperature_10km2 |
| nighttime_lights_point |
| nighttime_lights_1km2 |
| nighttime_lights_3km2 |
| nighttime_lights_5km2 |
| nighttime_lights_10km2 |
| human_population_density_point |
| human_population_density_1km2 |
| human_population_density_3km2 |
| human_population_density_5km2 |
| human_population_density_10km2 |
| protected_areas_point |
| protected_areas_1km2 |
| protected_areas_3km2 |
| protected_areas_5km2 |
| protected_areas_10km2 |
| GEEBAM_fire_severity_2020_point |
| GEEBAM_fire_severity_2020_1km2 |
| GEEBAM_fire_severity_2020_3km2 |
| GEEBAM_fire_severity_2020_5km2 |
| GEEBAM_fire_severity_2020_10km2 |
| HCAS_static_point |
| HCAS_static_1km2 |
| HCAS_static_3km2 |
| HCAS_static_5km2 |
| HCAS_static_10km2 |
| Olson_global_ecoregion |
| NDVI_point |
| NDVI_1km2 |
| NDVI_3km2 |
| NDVI_5km2 |
| NDVI_10km2 |
| terrain_ruggedness_index_point |
| terrain_ruggedness_index_1km2 |
| terrain_ruggedness_index_3km2 |
| terrain_ruggedness_index_5km2 |
| terrain_ruggedness_index_10km2 |
| standardized_precipitation_index_point |
| standardized_precipitation_index_1km2 |
| standardized_precipitation_index_3km2 |
| standardized_precipitation_index_5km2 |
| standardized_precipitation_index_10km2 |
| IBRAsubRegionName |
| IBRAbioRegionName |
# Store field groupings explicitly for further use
# Sorted list of fields shared by both tables
common_fields <- sort(intersect(names(deployments), names(covariates)))
# Fields unique to the deployments table
only_deploy <- sort(setdiff(names(deployments), names(covariates)))
# Fields unique to the covariates table
only_covs <- sort(setdiff(names(covariates), names(deployments)))
# Determine the maximum number of fields across the three groups
# This is required so all columns in the final tibble have equal length
max_len <- max(
length(common_fields),
length(only_deploy),
length(only_covs)
)
# Helper function to pad shorter vectors with NA values
# Ensures all vectors have the same length for tibble creation
pad <- function(x, n) {
c(x, rep(NA, n - length(x)))
}
# Combine the three field groups into a single side-by-side comparison table
field_table <- tibble::tibble(
common_fields = pad(common_fields, max_len),
only_in_deployments = pad(only_deploy, max_len),
only_in_covariates = pad(only_covs, max_len)
)
# Print the final comparison table
print(field_table)# A tibble: 73 × 3
common_fields only_in_deployments only_in_covariates
<chr> <chr> <chr>
1 deploymentEnd baitUse altitude_10km2
2 deploymentGroups cameraDelay altitude_1km2
3 deploymentID cameraDepth altitude_3km2
4 deploymentStart cameraHeading altitude_5km2
5 latitude cameraHeight altitude_point
6 locationID cameraID ecoregion_intactness_10km2
7 locationName cameraModel ecoregion_intactness_1km2
8 longitude cameraTilt ecoregion_intactness_3km2
9 projectName coordinateUncertainty ecoregion_intactness_5km2
10 source deploymentComments ecoregion_intactness_point
# ℹ 63 more rowsRead schema to understand covariates and choose which to include in your model. Each schema includes a description, data type (e.g., numeric or factor), spatial resolution, and constraints such as minimum and maximum values.
## Extract covariates schema from the data package
# Retrieve the Frictionless schema for the 'covariates' resource
# This schema defines the expected structure, types, and constraints
# for each covariate field (metadata, not the data itself)
covs_schema <- frictionless::get_schema(dp_list[[1]], "covariates")
## Convert schema to a tidy data frame
# Each field in the schema is stored as a nested list.
# Convert these field definitions into a tabular format for easier inspection.
covs_schema_df <- purrr::map_df(covs_schema$fields, ~{
# Extract relevant schema attributes for each field,
# using NA defaults where attributes are not defined
tibble::tibble(
name = .x$name %||% NA, # Field (column) name
description = .x$description %||% NA, # Human-readable description
type = .x$type %||% NA, # Expected data type
example = as.character(.x$example %||% NA), # Example value (if provided)
required = .x$constraints$required %||% NA, # Whether the field is mandatory
unique = .x$constraints$unique %||% NA, # Whether values must be unique
enum = paste( # Allowed values, if constrained
.x$constraints$enum %||% NA,
collapse = "|"
)
)
})
## Inspect the covariates schema
# Display the schema summary to quickly assess
# the number of fields and their declared constraints
glimpse(covs_schema_df)Rows: 82
Columns: 7
$ name <chr> "deploymentID", "locationID", "locationName", "latitude", …
$ description <chr> "Unique identifier of the deployment.", "Identifier of the…
$ type <chr> "string", "string", "string", "number", "number", "datetim…
$ example <chr> "dep1", "loc1", "Białowieża MRI 01", "52.7044", "23.8499",…
$ required <lgl> TRUE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE, FALSE, NA, NA,…
$ unique <lgl> TRUE, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ enum <chr> "NA", "NA", "NA", "NA", "NA", "NA", "NA", "NA", "NA", "NA"…This schema tells us what must exist, what may exist, and what should be chosen, making covariate selection a deliberate, defensible modelling step rather than a convenience decision.
## which variables are just characters?
unique(covs_schema_df$name[covs_schema_df$type == "string"])[1] "deploymentID" "locationID" "locationName"
[4] "deploymentGroups" "Olson_global_ecoregion" "IBRAsubRegionName"
[7] "IBRAbioRegionName" "projectName" ## which variables are numeric?
unique(covs_schema_df$name[covs_schema_df$type == "number"]) [1] "latitude"
[2] "longitude"
[3] "FLII_point"
[4] "FLII_1km2"
[5] "FLII_3km2"
[6] "FLII_5km2"
[7] "FLII_10km2"
[8] "human_footprint_point"
[9] "human_footprint_1km2"
[10] "human_footprint_3km2"
[11] "human_footprint_5km2"
[12] "human_footprint_10km2"
[13] "altitude_point"
[14] "altitude_1km2"
[15] "altitude_3km2"
[16] "altitude_5km2"
[17] "altitude_10km2"
[18] "ecoregion_intactness_point"
[19] "ecoregion_intactness_1km2"
[20] "ecoregion_intactness_3km2"
[21] "ecoregion_intactness_5km2"
[22] "ecoregion_intactness_10km2"
[23] "mean_monthly_precipitation_point"
[24] "mean_monthly_precipitation_1km2"
[25] "mean_monthly_precipitation_3km2"
[26] "mean_monthly_precipitation_5km2"
[27] "mean_monthly_precipitation_10km2"
[28] "mean_monthly_temperature_point"
[29] "mean_monthly_temperature_1km2"
[30] "mean_monthly_temperature_3km2"
[31] "mean_monthly_temperature_5km2"
[32] "mean_monthly_temperature_10km2"
[33] "nighttime_lights_point"
[34] "nighttime_lights_1km2"
[35] "nighttime_lights_3km2"
[36] "nighttime_lights_5km2"
[37] "nighttime_lights_10km2"
[38] "human_population_density_point"
[39] "human_population_density_1km2"
[40] "human_population_density_3km2"
[41] "human_population_density_5km2"
[42] "human_population_density_10km2"
[43] "protected_areas_point"
[44] "protected_areas_1km2"
[45] "protected_areas_3km2"
[46] "protected_areas_5km2"
[47] "protected_areas_10km2"
[48] "HCAS_static_point"
[49] "HCAS_static_1km2"
[50] "HCAS_static_3km2"
[51] "HCAS_static_5km2"
[52] "HCAS_static_10km2"
[53] "NDVI_point"
[54] "NDVI_1km2"
[55] "NDVI_3km2"
[56] "NDVI_5km2"
[57] "NDVI_10km2"
[58] "terrain_ruggedness_index_point"
[59] "terrain_ruggedness_index_1km2"
[60] "terrain_ruggedness_index_3km2"
[61] "terrain_ruggedness_index_5km2"
[62] "terrain_ruggedness_index_10km2"
[63] "standardized_precipitation_index_point"
[64] "standardized_precipitation_index_1km2"
[65] "standardized_precipitation_index_3km2"
[66] "standardized_precipitation_index_5km2"
[67] "standardized_precipitation_index_10km2"## which variables are required?
unique(covs_schema_df$name[covs_schema_df$required == TRUE]) # anything that wont generate an NA [1] "deploymentID"
[2] "latitude"
[3] "longitude"
[4] "deploymentStart"
[5] "deploymentEnd"
[6] NA
[7] "human_footprint_point"
[8] "human_footprint_1km2"
[9] "human_footprint_3km2"
[10] "human_footprint_5km2"
[11] "human_footprint_10km2"
[12] "altitude_point"
[13] "altitude_1km2"
[14] "altitude_3km2"
[15] "altitude_5km2"
[16] "altitude_10km2"
[17] "ecoregion_intactness_point"
[18] "ecoregion_intactness_1km2"
[19] "ecoregion_intactness_3km2"
[20] "ecoregion_intactness_5km2"
[21] "ecoregion_intactness_10km2"
[22] "mean_monthly_precipitation_point"
[23] "mean_monthly_precipitation_1km2"
[24] "mean_monthly_precipitation_3km2"
[25] "mean_monthly_precipitation_5km2"
[26] "mean_monthly_precipitation_10km2"
[27] "mean_monthly_temperature_point"
[28] "mean_monthly_temperature_1km2"
[29] "mean_monthly_temperature_3km2"
[30] "mean_monthly_temperature_5km2"
[31] "mean_monthly_temperature_10km2"
[32] "human_population_density_point"
[33] "human_population_density_1km2"
[34] "human_population_density_3km2"
[35] "human_population_density_5km2"
[36] "human_population_density_10km2"
[37] "protected_areas_point"
[38] "protected_areas_1km2"
[39] "protected_areas_3km2"
[40] "protected_areas_5km2"
[41] "protected_areas_10km2"
[42] "HCAS_static_point"
[43] "HCAS_static_1km2"
[44] "HCAS_static_3km2"
[45] "HCAS_static_5km2"
[46] "HCAS_static_10km2"
[47] "Olson_global_ecoregion"
[48] "NDVI_point"
[49] "NDVI_1km2"
[50] "NDVI_3km2"
[51] "NDVI_5km2"
[52] "NDVI_10km2"
[53] "terrain_ruggedness_index_point"
[54] "terrain_ruggedness_index_1km2"
[55] "terrain_ruggedness_index_3km2"
[56] "terrain_ruggedness_index_5km2"
[57] "terrain_ruggedness_index_10km2"
[58] "standardized_precipitation_index_point"
[59] "standardized_precipitation_index_1km2"
[60] "standardized_precipitation_index_3km2"
[61] "standardized_precipitation_index_5km2"
[62] "standardized_precipitation_index_10km2"
[63] "IBRAsubRegionName"
[64] "IBRAbioRegionName" Finally, all spatially derived covariates include a link to access the online source where the spatial data was accessed to provide more information. This is currently missing but will be fixed soon (see this issue on WildObs database for updates)
## whats the description of HCAS?
covs_schema_df$description[covs_schema_df$name == "HCAS_static_3km2"][1] "This variable represents the long-term (1988–2022) estimate of habitat condition across Australia, derived from the Habitat Condition Assessment System (HCAS v3.1). Condition values are calculated using a nationally consistent ecological model that incorporates vegetation structure, land use, connectivity, and degradation pressure, and are scaled from 0 to 1, where 1 = very high integrity and 0 = very low integrity. This variable has been calculated with a 977.2 meter buffer around each deploymentID."## Great, we know what the covariates are, we can remove the covs_schema
rm(covs_schema)Merge covariates with deployments by all shared columns to avoid duplication. Both tables are indexed by deploymentID, but the tables share the following columns: "deploymentID", "locationID", "locationName", "latitude", "longitude", "deploymentStart", "deploymentEnd", and "deploymentGroups".
## deployments and covaraites should both be indexed by deploymentID, make sure they match!
WildObsR::verify_col_match(deployments, covariates, col = "deploymentID") # full match! [1] "All values from the column: deploymentID match! Proceed with further data wrangling"# merge together based on shared cols so we have one less object to deal with
covariates = merge(deployments, covariates, by = names(covariates)[names(covariates) %in% names(deployments)])Convert all datetime strings into POSIXct data class to ensure data is recognized in a date-time format. This is particularly critical for deploymentStart and deploymentEnd in the deployments and observationStart and observationEnd in the observations data resources.
## format date-time columns
covariates$deploymentEnd = as.POSIXct(covariates$deploymentEnd, format = "%Y-%m-%dT%H:%M:%S%z")
covariates$deploymentStart = as.POSIXct(covariates$deploymentStart, format = "%Y-%m-%dT%H:%M:%S%z")
observations$observationStart = as.POSIXct(observations$observationStart, format = "%Y-%m-%dT%H:%M:%S%z")
observations$observationEnd = as.POSIXct(observations$observationEnd, format = "%Y-%m-%dT%H:%M:%S%z")Inspect deployment covariates and standardise any inconsistencies. A common field with potentially inconsistent values is the deploymentTags field that captures additional deployment related information beyond the camtrapDP standard. This field is formatted using key:value pairs that can be extracted to new columns.
This section standardises and parses the deploymentTags field, which often stores additional user-defined metadata such as bait type or predator-management activity. Tags are cleaned, split into key–value pairs, reshaped into separate covariate columns, and merged back into the main covariates table. This transforms previously unstructured text metadata into proper categorical covariates that can be included in the analysis as fixed effects or grouping variables. This likely will become a function to be used in the WildObsR package (see here for updates).
## Inpsect deploymentTags, where additional information beyond camtrapDP standards may be stored.
unique(covariates$deploymentTags) # Standardize values[1] "lure: none | predatorManagement: No management"# Finds all rows where deploymentTags matches any of the messy or inconsistent versions in the list (e.g., missing bait:none, inconsistent spacing, inconsistent capitalization).
# Replaces all those variations with one clean, standardised version:"bait:none | predatorManagement: No management"
covariates$deploymentTags[covariates$deploymentTags %in% c("lure:none | predatorManagement: No management",
" | predatorManagement: No management",
"lure:none | predatorManagement:no management",
"lure:none | predatorManagement:No management"
)] = "lure:none | predatorManagement: No management"Expand deploymentTags into separate columns in the deployments data resource (e.g., bait, predatorManagement) as new site-level covariates. You can also expand observationTags into separate columns in the observations data resource (e.g., temperature) as new observation-level covariates.
## Extract all tags into separate columns in covaraites
covs_with_tags <- covariates %>%
# create new cols to track original rows and split tags
dplyr::mutate(
row_id = dplyr::row_number(), # To track original rows
tag_list = stringr::str_split(deploymentTags, "\\s*\\|\\s*")
) %>%
tidyr::unnest(tag_list) %>%
# Remove blanks
filter(!is.na(tag_list), tag_list != "") %>%
# split keys and values
separate(tag_list, into = c("tag_key", "tag_value"), sep = ":", fill = "right") %>%
dplyr::mutate(
tag_key = str_trim(tag_key),
tag_value = str_trim(tag_value)
) %>%
pivot_wider(
id_cols = row_id,
names_from = tag_key,
values_from = tag_value
) %>%
right_join(
covariates %>% dplyr::mutate(row_id = dplyr::row_number()),
by = "row_id"
) %>%
select(-row_id)
# inspect
table(covs_with_tags$lure)
none
275 table(covs_with_tags$predatorManagement)
No management
275 This tells us that all 275 deployments share the same tag values:
Every deployment was recorded with bait:none, meaning no bait was used anywhere in the study. This can also be inspected by checking the logical true/false column
baitUse.Every deployment also has predatorManagement: No management, meaning no predator-control actions (e.g., trapping, poison, fencing) were active during any deployment.
## save these extra column names that we will use later
tag_cols = setdiff(names(covs_with_tags), names(covariates))1.3.5 Species selection
Step 3: Species selection
Select the species you are interested in. Can repeat the process of analyzing species occupancy for multiple species using for-loops. In this example we will select four species.
Understand the ecology of the species you have selected. An important consideration is the average home-range size of each species relative to the assumption of independence across sites. For example, if a species’ home range is larger than the average spacing between sampling sites and the same individual is detected across multiple sites, this violates a key assumption of the model (see here for more information). WildObs provides a data set that includes species traits, including home-range sizes, which were extracted from the
traitdataR package and matched with the WildObs species database.

Note
Source of the picture of each species:
Dingo: https://biocache.ala.org.au/occurrences/5ea25ebe-2e63-4b28-96e9-8dd98b80e55d
Feral Cat: https://biocache.ala.org.au/occurrences/5a1d30c2-96cf-4f7e-a832-60944583fca4
Lace monitor: https://biocache.ala.org.au/occurrences/53c5d6e7-3b22-442d-a068-0ab9b2791bfe
Chowchilla: https://biocache.ala.org.au/occurrences/b98c136f-7455-44ea-879e-2ae0ca2db8ed
sp = c("Canis dingo", # Dingo
"Felis catus", # Feral cat
"Orthonyx spaldingii", # Chowchilla
"Varanus varius" # Lace Monitor
)1.3.6 Spatial resampling
Step 4: Spatial resampling
Spatial resampling is the process of aggregating camera deployments and observations into spatially discrete sampling units. This process is achieved by creating a grid of hexagons covering a specific area, and aggregating deployments and observations per date. This process ensures comparability among landscapes, reduces spatial pseudo-replication, and, by using a sampling unit size larger than the species’ home range, ensures that occupancy is being measured, as opposed to habitat use.
For more information on spatial resampling for occupancy model, please see the method sections of Amir et al. (2022), Anderson et al. (2025), and Linkie (2020).
The WildObsR R library provides two functions to facilitate resampling: WildObsR::spatial_hexagon_generator() to generate the grid of hexagons and WildObsR::resample_covariates_and_observations() to use the grid of hexagons to resample the data.
First, using the home range sizes for each species, ensure sizes are converted to m² as the resampling scale.
Use the
WildObsR::spatial_hexagon_generator()function to generate hexagonal sampling units at multiple scales (1 km², 3 km², 6 km², 65 km²) based on species home range.Examine and summarise sampling efforts by inspecting important columns like number of deployments and hexagonal sampling units, duration of deployments, and calculating new columns like sampling effort, expressed as trap nights.
Importantly, the field
deploymentGroupshas been calculated through the WildObs data curation process to describe spatially (i.e., within one landscape, denoted as locationName) and temporally (i.e., 100 days maximum in duration) distinct sampling efforts (i.e., surveys).Remove deploymentGroups that don’t meet inclusion criteria (too short, too few sites, >120 days, multiple landscapes, repeated deployments). This ensures robust surveys are included in the analysis and results wont be skewed by small sample sizes.
Keep only robust deployments and matching observations that fall within deploymentGroups of sufficent size.
Use the
WildObsR::resample_covariates_and_observations()function to spatially resample covariates and observations across multiple spatial scales. This function changes the structure of the data in several important ways.First, it removes any time-related information and summarizes observations per day. The function also calculates revised sampling effort per sampling unit (i.e., rather than per deployment) to account for multiple deployments within a single sampling unit.
A new observation-level covariate,
numberDeploymentsActiveAtDate, describes how many deployments were active within a sampling unit on each day and serves as a high-resolution observation-level covariate for sampling effort. You can also include additional observation-level covariates from the covariates table in the observations table (e.g.,featureType).- For example, if two deployments placed on different features are resampled into the same sampling unit, you can include
featureTypeto denote which deployment and corresponding feature generated the observation.
- For example, if two deployments placed on different features are resampled into the same sampling unit, you can include
Finally, it is important to consider whether to aggregate the number of individuals detected per day by taking the maximum or the sum across all detections. For a full description of this function and its options, see the help page:
?WildObsR::resample_covariates_and_observations()
Species traits
There is a built-in data WildObsR dataset called species_traits in which you can find some information about a species. Here, we care about the home range for species, as we need to use this information to make decisions on the spatial resampling.
library(WildObsR)
data("species_traits")
head(species_traits)# A tibble: 6 × 14
binomial_verified uri phylum class order family genus species home_range_km2
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <dbl>
1 Acanthagenys ruf… http… Chord… Aves Pass… Melip… Acan… Acanth… NA
2 Acanthiza apical… http… Chord… Aves Pass… Acant… Acan… Acanth… NA
3 Acanthiza chryso… http… Chord… Aves Pass… Acant… Acan… Acanth… NA
4 Acanthiza lineata http… Chord… Aves Pass… Acant… Acan… Acanth… NA
5 Acanthiza nana http… Chord… Aves Pass… Acant… Acan… Acanth… NA
6 Acanthiza pusilla http… Chord… Aves Pass… Acant… Acan… Acanth… NA
# ℹ 5 more variables: home_range_source <chr>, AdultBodyMass_g <dbl>,
# bodyMass_source <chr>, epbc_category <fct>, epbc_location <chr>traits <- species_traits## check if species are present
setdiff(sp, traits$binomial_verified) # all are present!character(0)## reduce to the relevant species
traits = traits[traits$binomial_verified %in% sp, ]
# Check for missing home-range values
anyNA(traits$home_range_km2) # true![1] TRUEtraits[, c("binomial_verified", "home_range_km2")]# A tibble: 4 × 2
binomial_verified home_range_km2
<chr> <dbl>
1 Canis dingo NA
2 Felis catus 5.88
3 Orthonyx spaldingii NA
4 Varanus varius NA From the table above, home-range information is incomplete for several species. We only have reliable data for Feral cat, which typically remains within approximately 6 km of its home range. For dingo, lace monitor, and chowchilla, home-range values are currently unknown. We will need to identify suitable surrogate estimates to fill these gaps.
To proceed, we will apply surrogate values: 6 km for dingo, and 1 km for both lace monitor and chowchilla as our current best estimates. Dingoes have unusually large or variable home-range estimates. To avoid under-estimating their spatial scale, they are assigned the maximum available home-range value (6,000,000 m² in our subset of four species).
Species without home-range estimates (e.g., Orthonyx spaldingii, Varanus varius) are given a default of:
- 1 km² = 1,000,000 m²
This ensures every species has a usable scale for spatial resampling.
# convert to m2
traits$home_range_m2 = ceiling(traits$home_range_km2 * 1e6 / 1e6) * 1e6 # but round to the nearest 1km2
# Make dingo home-ranges same as biggest option
traits$home_range_m2[traits$binomial_verified == "Canis dingo"] <- max(traits$home_range_m2, na.rm = T)
# and all others default to 1km
traits$home_range_m2[is.na(traits$home_range_m2)] = 1e6
traits %>%
select(binomial_verified, home_range_km2, home_range_m2) %>%
arrange(desc(home_range_m2)) %>%
print()# A tibble: 4 × 3
binomial_verified home_range_km2 home_range_m2
<chr> <dbl> <dbl>
1 Canis dingo NA 6000000
2 Felis catus 5.88 6000000
3 Orthonyx spaldingii NA 1000000
4 Varanus varius NA 1000000# Create spatial hexagons based on species home-range scales
## Save this info as scales to resample
scales = unique(sort(traits$home_range_m2))
# scales should contain only: 1e6 (1 km2) and 6e6 (6 km2)
scales[1] 1e+06 6e+06# [1] 1e6 6e6
covs_cellIDs <- WildObsR::spatial_hexagon_generator(
data = covs_with_tags,
scales = scales
)
### Inspect generated hexagon columns
hex_cols <- names(covs_cellIDs)[grepl("cellID", names(covs_cellIDs))]
hex_cols[1] "cellID_1km2" "cellID_6km2"# Expect: "cellID_1km2", "cellID_6km2"
length(unique(covs_cellIDs$cellID_1km2))[1] 144length(unique(covs_cellIDs$cellID_6km2))[1] 114# Summarise deploymentGroup robustness
surv_summary <- ddply(
covs_cellIDs,
.(deploymentGroups),
summarize,
num_su_1km = length(unique(cellID_1km2)), # 1 km2 sampling units
num_su_6km = length(unique(cellID_6km2)), # 6 km2 sampling units
num_land = length(unique(locationName)), # number of locations in the group
dur = as.numeric(
difftime(
max(deploymentEnd),
min(deploymentStart),
units = "days"
)
)
)
# Calculate trap-nights (sampling effort)
surv_summary$trap_nights <- surv_summary$num_su_1km * surv_summary$dur
# Inspect (sorted)
surv_summary[order(surv_summary$trap_nights), ] deploymentGroups num_su_1km num_su_6km num_land
3 Eacham_Curtain_Fig_NPs_2022_Amir 16 9 1
4 Mount_Lewis_NP_2022_Amir 22 18 1
1 Daintree_NP_2022_Amir 24 23 1
2 Danbulla_NP_2022_Amir 21 18 1
5 Wooroonooran_Goldfield_Track_2022_Amir 26 20 1
6 Wooroonooran_NP_2022_Amir 35 26 1
dur trap_nights
3 82.29579 1316.733
4 78.66123 1730.547
1 77.98822 1871.717
2 92.99595 1952.915
5 94.84572 2465.989
6 89.13432 3119.701# Identify deploymentGroups to remove
# 1. low sampling effort
rm1 <- surv_summary$deploymentGroups[surv_summary$trap_nights < 100]
# 2. very long surveys (>120 days)
rm3 <- surv_summary$deploymentGroups[surv_summary$dur > 120]
# 3. multiple landscapes in one deploymentGroup (should be 1)
rm4 <- surv_summary$deploymentGroups[surv_summary$num_land > 1]
# 4. repeated deployments
rm5 <- unique(covs_cellIDs$deploymentGroups[
duplicated(covs_cellIDs$deploymentID)
])
# Combine
rm <- unique(c(rm1, rm3, rm4, rm5))
rmcharacter(0)# Quantify loss of observations if removed
lost_pct <- round(
nrow(observations[
observations$deploymentID %in%
covs_cellIDs$deploymentID[covs_cellIDs$deploymentGroups %in% rm],
]) / nrow(observations) * 100,
3
)
lost_pct[1] 0# percentage of observations removed
# Apply filtering to covariates and observations
covs_cellIDs <- covs_cellIDs[
!covs_cellIDs$deploymentGroups %in% rm,
]
observations <- observations[
observations$deploymentID %in% covs_cellIDs$deploymentID,
]
# Result check
nrow(covs_cellIDs)[1] 275length(unique(covs_cellIDs$deploymentGroups))[1] 6length(unique(observations$deploymentID))[1] 275# Spatial resampling: aggregate covariates & observations
# This step aligns detections and covariates to spatial sampling units
# (hexagons), approximating species' home-range scales.
# Note: this step may take several minutes depending on dataset size.
# 1. Select columns to aggregate using MODE (categorical fields)
mode_cols_covs <- names(covs_cellIDs)[
grepl("source|IBRAsubRegionName|GEEBAM", names(covs_cellIDs))
]
# These variables represent attributes where the most common value
# should be retained after resampling.
# 2. Choose how to aggregate multiple individuals per window
individuals <- "max" # Alternatives: "sum"
# 3. Observation-level covariates (dynamic, detection-level)
obs_covs <- c(
"baitUse",
"featureType",
"setupBy",
"cameraHeight",
"cameraModel"
)
# These vary between deployments and through time.
# 4. Run spatial resampling
start <- Sys.time()
resampled_data <- resample_covariates_and_observations(
covs = covs_cellIDs,
obs = observations,
individuals = individuals,
mode_cols_covs = mode_cols_covs,
obs_covs = obs_covs
)
end <- Sys.time()
end - start # runtime informationTime difference of 3.349816 mins# 5. Inspect resampled results (correct scales only: 1km2, 6km2)
glimpse(resampled_data$spatially_resampled_covariates$cellID_1km2)Rows: 144
Columns: 99
$ cellID_1km2 <chr> "Eacham_Curtain_Fig_NPs_82_…
$ polygon_1km2 <chr> "Eacham_Curtain_Fig_NPs_82_…
$ Avg_latitude <dbl> -17.2911, -17.2885, -17.281…
$ Avg_longitude <dbl> 145.6316, 145.6295, 145.629…
$ Avg_coordinateUncertainty <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ Avg_cameraDelay <dbl> 0.0, 0.0, 0.0, 0.0, 0.0, 0.…
$ Avg_cameraHeight <dbl> 0.3, 0.3, 0.3, 0.3, 0.3, 0.…
$ Avg_cameraTilt <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_FLII_point <dbl> 1.7080, 0.4250, 0.0000, 0.7…
$ Avg_FLII_1km2 <dbl> 0.7363, 0.6608, 1.3082, 1.7…
$ Avg_FLII_3km2 <dbl> 0.8721, 1.0481, 1.7096, 1.5…
$ Avg_FLII_5km2 <dbl> 1.0952, 1.0842, 1.5739, 1.3…
$ Avg_FLII_10km2 <dbl> 1.2343, 1.2919, 1.2791, 1.3…
$ Avg_human_footprint_point <dbl> 11, 11, 11, 11, 7, 11, 3, 1…
$ Avg_human_footprint_1km2 <dbl> 11.00, 11.00, 11.00, 11.00,…
$ Avg_human_footprint_3km2 <dbl> 9.6667, 9.6667, 10.0000, 11…
$ Avg_human_footprint_5km2 <dbl> 8.3333, 8.6000, 10.0000, 10…
$ Avg_human_footprint_10km2 <dbl> 7.5556, 7.9000, 8.2000, 9.8…
$ Avg_altitude_point <dbl> 814.0001, 787.0001, 770.000…
$ Avg_altitude_1km2 <dbl> 776.4581, 777.4284, 766.613…
$ Avg_altitude_3km2 <dbl> 766.0306, 768.9528, 766.595…
$ Avg_altitude_5km2 <dbl> 762.8160, 765.9388, 764.158…
$ Avg_altitude_10km2 <dbl> 761.0627, 759.2821, 754.419…
$ Avg_ecoregion_intactness_point <dbl> 0.041, 0.094, 0.094, 0.040,…
$ Avg_ecoregion_intactness_1km2 <dbl> 0.0410, 0.0652, 0.0538, 0.0…
$ Avg_ecoregion_intactness_3km2 <dbl> 0.0737, 0.0652, 0.0538, 0.0…
$ Avg_ecoregion_intactness_5km2 <dbl> 0.0652, 0.0652, 0.0538, 0.0…
$ Avg_ecoregion_intactness_10km2 <dbl> 0.0750, 0.0800, 0.0852, 0.0…
$ Avg_mean_monthly_precipitation_point <dbl> 225.4710, 214.7532, 214.753…
$ Avg_mean_monthly_precipitation_1km2 <dbl> 225.4710, 219.9265, 217.079…
$ Avg_mean_monthly_precipitation_3km2 <dbl> 219.9265, 219.9265, 217.079…
$ Avg_mean_monthly_precipitation_5km2 <dbl> 219.9265, 219.9265, 217.079…
$ Avg_mean_monthly_precipitation_10km2 <dbl> 223.7736, 218.8610, 217.697…
$ Avg_mean_monthly_temperature_point <dbl> 23.5127, 23.3538, 23.3538, …
$ Avg_mean_monthly_temperature_1km2 <dbl> 23.5127, 23.4952, 23.5200, …
$ Avg_mean_monthly_temperature_3km2 <dbl> 23.4952, 23.4952, 23.5200, …
$ Avg_mean_monthly_temperature_5km2 <dbl> 23.4952, 23.4952, 23.5200, …
$ Avg_mean_monthly_temperature_10km2 <dbl> 23.4574, 23.5174, 23.5158, …
$ Avg_nighttime_lights_point <dbl> 0.2676, 0.2799, 0.3466, 0.3…
$ Avg_nighttime_lights_1km2 <dbl> 0.2698, 0.2703, 0.3410, 0.3…
$ Avg_nighttime_lights_3km2 <dbl> 0.2759, 0.2817, 0.3298, 0.3…
$ Avg_nighttime_lights_5km2 <dbl> 0.2781, 0.2945, 0.3129, 0.3…
$ Avg_nighttime_lights_10km2 <dbl> 0.2880, 0.3057, 0.3160, 0.3…
$ Avg_human_population_density_point <dbl> 90.8647, 5.7992, 5.7992, 0.…
$ Avg_human_population_density_1km2 <dbl> 90.8647, 29.0116, 5.7992, 0…
$ Avg_human_population_density_3km2 <dbl> 38.6821, 29.0116, 6.0283, 6…
$ Avg_human_population_density_5km2 <dbl> 29.0116, 29.0116, 6.0283, 6…
$ Avg_human_population_density_10km2 <dbl> 35.7631, 27.2437, 18.7278, …
$ Avg_protected_areas_point <dbl> 1, 1, 1, 1, 1, 0, 0, 1, 1, …
$ Avg_protected_areas_1km2 <dbl> 0.2500, 0.7500, 1.0000, 1.0…
$ Avg_protected_areas_3km2 <dbl> 0.2308, 0.4615, 0.9091, 0.9…
$ Avg_protected_areas_5km2 <dbl> 0.2500, 0.4211, 0.7619, 0.8…
$ Avg_protected_areas_10km2 <dbl> 0.3659, 0.4250, 0.5250, 0.5…
$ Avg_GEEBAM_fire_severity_2020_point <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_GEEBAM_fire_severity_2020_1km2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_GEEBAM_fire_severity_2020_3km2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_GEEBAM_fire_severity_2020_5km2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_GEEBAM_fire_severity_2020_10km2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_HCAS_static_point <dbl> 0.7983, 0.8639, 0.8265, 0.8…
$ Avg_HCAS_static_1km2 <dbl> 0.6660, 0.6125, 0.6801, 0.7…
$ Avg_HCAS_static_3km2 <dbl> 0.5114, 0.5487, 0.6949, 0.6…
$ Avg_HCAS_static_5km2 <dbl> 0.4372, 0.5380, 0.7033, 0.5…
$ Avg_HCAS_static_10km2 <dbl> 0.3969, 0.4603, 0.5008, 0.4…
$ Avg_NDVI_point <dbl> 0.3517, 0.3644, 0.3644, 0.3…
$ Avg_NDVI_1km2 <dbl> 0.3517, 0.3566, 0.4009, 0.3…
$ Avg_NDVI_3km2 <dbl> 0.3566, 0.3566, 0.4009, 0.3…
$ Avg_NDVI_5km2 <dbl> 0.3566, 0.3566, 0.4009, 0.3…
$ Avg_NDVI_10km2 <dbl> 0.3587, 0.3779, 0.3957, 0.3…
$ Avg_terrain_ruggedness_index_point <dbl> 11.1250, 7.3750, 7.0000, 11…
$ Avg_terrain_ruggedness_index_1km2 <dbl> 7.3061, 7.0553, 6.9049, 10.…
$ Avg_terrain_ruggedness_index_3km2 <dbl> 6.6520, 7.1442, 7.7441, 8.3…
$ Avg_terrain_ruggedness_index_5km2 <dbl> 6.4218, 7.3707, 8.3060, 8.2…
$ Avg_terrain_ruggedness_index_10km2 <dbl> 6.7620, 7.1193, 7.8438, 7.7…
$ Avg_standardized_precipitation_index_point <dbl> 0.6759, 0.6759, 0.6759, 0.6…
$ Avg_standardized_precipitation_index_1km2 <dbl> 0.6759, 0.6759, 0.6759, 0.6…
$ Avg_standardized_precipitation_index_3km2 <dbl> 0.5914, 0.6759, 0.6759, 0.6…
$ Avg_standardized_precipitation_index_5km2 <dbl> 0.5914, 0.6759, 0.6759, 0.6…
$ Avg_standardized_precipitation_index_10km2 <dbl> 0.5914, 0.6759, 0.6759, 0.6…
$ mode_source <chr> "Z_Amir", "Z_Amir", "Z_Amir…
$ mode_IBRAsubRegionName <chr> "Bellenden Ker-Lamb", "Bell…
$ deploymentsIncluded <chr> "CFRAG_01_2022_Cam1 - CFRAG…
$ lure <chr> "none", "none", "none", "no…
$ predatorManagement <chr> "No management", "No manage…
$ locationID <chr> "CFRAG_01", "CFRAG_02", "CF…
$ locationName <chr> "Eacham_Curtain_Fig_NPs", "…
$ deploymentGroups <chr> "Eacham_Curtain_Fig_NPs_202…
$ projectName <chr> "ZAmir_QLD_Wet_Tropics_2022…
$ setupBy <chr> "ZA SK", "ZA SK", "ZA SK", …
$ cameraID <chr> "2065144", "2065144", "2065…
$ cameraModel <chr> "Reconyx", "Reconyx", "Reco…
$ habitat <chr> "tropical rainforest", "tro…
$ deploymentTags <chr> "lure: none | predatorManag…
$ deploymentComments <chr> "& SD card = Oo2 & physical…
$ multiSeason_deploymentGroup <chr> "Eacham_Curtain_Fig_NPs_202…
$ Olson_global_ecoregion <chr> "Biome: 1, name: Queensland…
$ IBRAbioRegionName <chr> "Wet Tropics", "Wet Tropics…
$ cellEffort <dbl> 143.29455, 141.05119, 159.7…
$ samplingStart <dttm> 2022-12-15 08:19:27, 2022-…
$ samplingEnd <dttm> 2023-03-06 13:29:49, 2023-…glimpse(resampled_data$spatially_resampled_covariates$cellID_6km2)Rows: 114
Columns: 99
$ cellID_6km2 <chr> "Eacham_Curtain_Fig_NPs_23_…
$ polygon_6km2 <chr> "Eacham_Curtain_Fig_NPs_23_…
$ Avg_latitude <dbl> -17.28917, -17.28150, -17.2…
$ Avg_longitude <dbl> 145.6286, 145.6253, 145.614…
$ Avg_coordinateUncertainty <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ Avg_cameraDelay <dbl> 0.00, 0.00, 0.25, 0.00, 0.0…
$ Avg_cameraHeight <dbl> 0.3, 0.3, 0.3, 0.3, 0.3, 0.…
$ Avg_cameraTilt <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_FLII_point <dbl> 0.8834333, 0.8135750, 0.000…
$ Avg_FLII_1km2 <dbl> 0.7892333, 1.2762500, 0.855…
$ Avg_FLII_3km2 <dbl> 0.8976667, 1.4267750, 0.852…
$ Avg_FLII_5km2 <dbl> 1.030800, 1.340625, 1.05140…
$ Avg_FLII_10km2 <dbl> 1.276600, 1.310275, 1.17040…
$ Avg_human_footprint_point <dbl> 11, 10, 7, 11, 3, 19, 19, 1…
$ Avg_human_footprint_1km2 <dbl> 11.00, 10.00, 7.00, 11.00, …
$ Avg_human_footprint_3km2 <dbl> 9.444467, 9.916675, 9.00000…
$ Avg_human_footprint_5km2 <dbl> 8.644433, 9.716675, 9.53335…
$ Avg_human_footprint_10km2 <dbl> 8.040767, 9.100000, 9.11110…
$ Avg_altitude_point <dbl> 800.6667, 772.5000, 755.000…
$ Avg_altitude_1km2 <dbl> 774.9106, 769.9308, 739.373…
$ Avg_altitude_3km2 <dbl> 767.3759, 761.9200, 734.936…
$ Avg_altitude_5km2 <dbl> 763.3565, 757.2319, 731.888…
$ Avg_altitude_10km2 <dbl> 757.3053, 747.9493, 728.407…
$ Avg_ecoregion_intactness_point <dbl> 0.05833333, 0.05350000, 0.0…
$ Avg_ecoregion_intactness_1km2 <dbl> 0.04873333, 0.04345000, 0.0…
$ Avg_ecoregion_intactness_3km2 <dbl> 0.067300, 0.053575, 0.06150…
$ Avg_ecoregion_intactness_5km2 <dbl> 0.06886667, 0.05255000, 0.0…
$ Avg_ecoregion_intactness_10km2 <dbl> 0.07193333, 0.06540000, 0.0…
$ Avg_mean_monthly_precipitation_point <dbl> 218.3258, 214.0490, 206.610…
$ Avg_mean_monthly_precipitation_1km2 <dbl> 220.0502, 214.6305, 203.848…
$ Avg_mean_monthly_precipitation_3km2 <dbl> 218.6064, 213.6127, 205.305…
$ Avg_mean_monthly_precipitation_5km2 <dbl> 218.3548, 214.0024, 203.470…
$ Avg_mean_monthly_precipitation_10km2 <dbl> 218.8263, 213.5929, 205.648…
$ Avg_mean_monthly_temperature_point <dbl> 23.40677, 23.41710, 23.4741…
$ Avg_mean_monthly_temperature_1km2 <dbl> 23.45390, 23.45865, 23.5780…
$ Avg_mean_monthly_temperature_3km2 <dbl> 23.48400, 23.47368, 23.5813…
$ Avg_mean_monthly_temperature_5km2 <dbl> 23.49197, 23.51785, 23.6240…
$ Avg_mean_monthly_temperature_10km2 <dbl> 23.50943, 23.55187, 23.6399…
$ Avg_nighttime_lights_point <dbl> 0.2738333, 0.3599250, 0.842…
$ Avg_nighttime_lights_1km2 <dbl> 0.275700, 0.353125, 0.73260…
$ Avg_nighttime_lights_3km2 <dbl> 0.2880667, 0.3555000, 0.591…
$ Avg_nighttime_lights_5km2 <dbl> 0.2935667, 0.3506500, 0.517…
$ Avg_nighttime_lights_10km2 <dbl> 0.3118333, 0.3620250, 0.421…
$ Avg_human_population_density_point <dbl> 32.22130, 1.44980, 4.85725,…
$ Avg_human_population_density_1km2 <dbl> 39.95877, 1.44980, 4.85725,…
$ Avg_human_population_density_3km2 <dbl> 25.79497, 4.79970, 4.79450,…
$ Avg_human_population_density_5km2 <dbl> 27.285000, 6.023025, 4.7442…
$ Avg_human_population_density_10km2 <dbl> 27.60930, 15.48307, 9.96125…
$ Avg_protected_areas_point <dbl> 1.0, 1.0, 0.5, 0.0, 0.0, 1.…
$ Avg_protected_areas_1km2 <dbl> 0.5000, 1.0000, 0.3750, 0.2…
$ Avg_protected_areas_3km2 <dbl> 0.4615333, 0.9126000, 0.384…
$ Avg_protected_areas_5km2 <dbl> 0.4166667, 0.7357000, 0.385…
$ Avg_protected_areas_10km2 <dbl> 0.4099667, 0.5062500, 0.308…
$ Avg_GEEBAM_fire_severity_2020_point <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_GEEBAM_fire_severity_2020_1km2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_GEEBAM_fire_severity_2020_3km2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_GEEBAM_fire_severity_2020_5km2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_GEEBAM_fire_severity_2020_10km2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ Avg_HCAS_static_point <dbl> 0.848900, 0.853275, 0.33600…
$ Avg_HCAS_static_1km2 <dbl> 0.5599333, 0.6557750, 0.342…
$ Avg_HCAS_static_3km2 <dbl> 0.524100, 0.636725, 0.31625…
$ Avg_HCAS_static_5km2 <dbl> 0.4911667, 0.6073250, 0.287…
$ Avg_HCAS_static_10km2 <dbl> 0.4301333, 0.4571750, 0.249…
$ Avg_NDVI_point <dbl> 0.3601667, 0.3720250, 0.343…
$ Avg_NDVI_1km2 <dbl> 0.3575667, 0.3811500, 0.345…
$ Avg_NDVI_3km2 <dbl> 0.35110, 0.37860, 0.35970, …
$ Avg_NDVI_5km2 <dbl> 0.3559333, 0.3827000, 0.349…
$ Avg_NDVI_10km2 <dbl> 0.3636333, 0.3784750, 0.345…
$ Avg_terrain_ruggedness_index_point <dbl> 12.20833, 12.00000, 7.50000…
$ Avg_terrain_ruggedness_index_1km2 <dbl> 7.484333, 8.299150, 6.85490…
$ Avg_terrain_ruggedness_index_3km2 <dbl> 7.243167, 8.174625, 6.93995…
$ Avg_terrain_ruggedness_index_5km2 <dbl> 7.114467, 8.280125, 6.88310…
$ Avg_terrain_ruggedness_index_10km2 <dbl> 6.949367, 7.561550, 6.48260…
$ Avg_standardized_precipitation_index_point <dbl> 0.6759, 0.6759, 0.6759, 0.6…
$ Avg_standardized_precipitation_index_1km2 <dbl> 0.6759, 0.6759, 0.6759, 0.6…
$ Avg_standardized_precipitation_index_3km2 <dbl> 0.6477333, 0.6759000, 0.675…
$ Avg_standardized_precipitation_index_5km2 <dbl> 0.6477333, 0.6759000, 0.675…
$ Avg_standardized_precipitation_index_10km2 <dbl> 0.6477333, 0.6759000, 0.675…
$ mode_source <chr> "Z_Amir", "Z_Amir", "Z_Amir…
$ mode_IBRAsubRegionName <chr> "Bellenden Ker-Lamb", "Athe…
$ deploymentsIncluded <chr> "CFRAG_01_2022_Cam1 - CFRAG…
$ lure <chr> "none", "none", "none", "no…
$ predatorManagement <chr> "No management", "No manage…
$ locationID <chr> "CFRAG_01 - CFRAG_02 - CFRA…
$ locationName <chr> "Eacham_Curtain_Fig_NPs", "…
$ deploymentGroups <chr> "Eacham_Curtain_Fig_NPs_202…
$ projectName <chr> "ZAmir_QLD_Wet_Tropics_2022…
$ setupBy <chr> "ZA SK", "ZA SK", "ZA - ZA …
$ cameraID <chr> "2065144", "2065144", "2065…
$ cameraModel <chr> "Reconyx", "Reconyx", "Reco…
$ habitat <chr> "tropical rainforest", "tro…
$ deploymentTags <chr> "lure: none | predatorManag…
$ deploymentComments <chr> "& SD card = Oo2 & physical…
$ multiSeason_deploymentGroup <chr> "Eacham_Curtain_Fig_NPs_202…
$ Olson_global_ecoregion <chr> "Biome: 1, name: Queensland…
$ IBRAbioRegionName <chr> "Wet Tropics", "Wet Tropics…
$ cellEffort <dbl> 348.68153, 498.16241, 147.6…
$ samplingStart <dttm> 2022-12-15 08:19:27, 2022-…
$ samplingEnd <dttm> 2023-03-07 14:11:01, 2023-…glimpse(resampled_data$spatially_resampled_observations$cellID_1km2)Rows: 33,592
Columns: 32
$ cellID_1km2 <chr> "Eacham_Curtain_Fig_NPs_82_cellID_1km2_2…
$ observationID <chr> "CFRAG_01_bush_20221215_Z_Amir_observati…
$ eventID <chr> "CFRAG_01_bush_20221215_Z_Amir_triggerEv…
$ scientificName <chr> "Blank", "Mammalia", "Thylogale stigmati…
$ behavior <chr> "", "", "", "", "", "", "", "", "", "", …
$ classifiedBy <chr> "Zachary Amir", "Zachary Amir", "Zachary…
$ observationComments <chr> "", "", "", "", "", "", "", "", "", "", …
$ projectName <chr> "ZAmir_QLD_Wet_Tropics_2022_WildObsID_00…
$ taxonID <chr> "", "https://www.ncbi.nlm.nih.gov/taxono…
$ taxonRank <chr> "", "class", "species", "species", "", "…
$ vernacularNamesEnglish <chr> "", "mammals", "red-legged pademelon", "…
$ source <chr> "Z_Amir", "Z_Amir", "Z_Amir", "Z_Amir", …
$ observationLevel <chr> "event", "event", "event", "event", "eve…
$ observationType <chr> "blank", "animal", "animal", "animal", "…
$ lifeStage <chr> "", "", "", "", "", "", "", "", "", "", …
$ sex <chr> "", "", "", "", "", "", "", "", "", "", …
$ classificationMethod <chr> "human", "human", "human", "human", "hum…
$ eventStart <dttm> 2022-12-18 11:58:11, 2022-12-18 11:58:1…
$ eventEnd <dttm> 2022-12-19 09:56:12, 2022-12-19 09:56:1…
$ observationStart <dttm> 2022-12-18 11:58:11, 2022-12-18 11:58:1…
$ observationEnd <dttm> 2022-12-19 10:08:53, 2022-12-19 10:08:5…
$ classificationProbability <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ baitUse <chr> "FALSE", "FALSE", "FALSE", "FALSE", "FAL…
$ featureType <chr> "trailHiking", "", "", "trailHiking", "t…
$ setupBy <chr> "ZA SK", "ZA SK", "ZA SK", "ZA SK", "ZA …
$ cameraHeight <chr> "0.3", "0.3", "0.3", "0.3", "0.3", "0.3"…
$ cameraModel <chr> "Reconyx", "Reconyx", "Reconyx", "Recony…
$ deploymentsActiveAtDate <chr> "CFRAG_01_2022_Cam1 - CFRAG_01_2022_Cam2…
$ numberDeploymentsActiveAtDate <int> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
$ independentEvents <int> 6, 1, 1, 5, 11, 9, 1, 2, 2, 1, 4, 2, 2, …
$ independentObservations <int> 5, 1, 1, 4, 9, 6, 1, 2, 2, 1, 4, 2, 2, 3…
$ totalIndividuals <dbl> 1, 1, 1, 1, 1, 2, 1, 1, 2, 1, 1, 1, 2, 2…glimpse(resampled_data$spatially_resampled_observations$cellID_6km2)Rows: 30,352
Columns: 32
$ cellID_6km2 <chr> "Eacham_Curtain_Fig_NPs_23_cellID_6km2_2…
$ observationID <chr> "CFRAG_01_bush_20221215_Z_Amir_observati…
$ eventID <chr> "CFRAG_01_bush_20221215_Z_Amir_triggerEv…
$ scientificName <chr> "Blank", "Mammalia", "Thylogale stigmati…
$ behavior <chr> "", "", "", "", "", "", "", "", "", "", …
$ classifiedBy <chr> "Zachary Amir", "Zachary Amir", "Zachary…
$ observationComments <chr> "", "", "", "", "", "", "", "", "", "", …
$ projectName <chr> "ZAmir_QLD_Wet_Tropics_2022_WildObsID_00…
$ taxonID <chr> "", "https://www.ncbi.nlm.nih.gov/taxono…
$ taxonRank <chr> "", "class", "species", "species", "spec…
$ vernacularNamesEnglish <chr> "", "mammals", "red-legged pademelon", "…
$ source <chr> "Z_Amir", "Z_Amir", "Z_Amir", "Z_Amir", …
$ observationLevel <chr> "event", "event", "event", "event", "eve…
$ observationType <chr> "blank", "animal", "animal", "animal", "…
$ lifeStage <chr> "", "", "", "", "", "", "", "", "", "", …
$ sex <chr> "", "", "", "", "", "", "", "", "", "", …
$ classificationMethod <chr> "human", "human", "human", "human", "hum…
$ eventStart <dttm> 2022-12-18 10:35:57, 2022-12-18 10:35:5…
$ eventEnd <dttm> 2022-12-19 09:58:47, 2022-12-19 09:58:4…
$ observationStart <dttm> 2022-12-18 10:35:57, 2022-12-18 10:35:5…
$ observationEnd <dttm> 2022-12-19 10:08:53, 2022-12-19 10:08:5…
$ classificationProbability <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ baitUse <chr> "FALSE", "FALSE", "FALSE", "FALSE", "FAL…
$ featureType <chr> "trailHiking", "", "trailHiking", "trail…
$ setupBy <chr> "ZA SK", "ZA SK", "ZA SK", "ZA SK", "ZA …
$ cameraHeight <chr> "0.3", "0.3", "0.3", "0.3", "0.3", "0.3"…
$ cameraModel <chr> "Reconyx", "Reconyx", "Reconyx", "Recony…
$ deploymentsActiveAtDate <chr> "CFRAG_01_2022_Cam1 - CFRAG_01_2022_Cam2…
$ numberDeploymentsActiveAtDate <int> 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6…
$ independentEvents <int> 25, 1, 2, 13, 3, 20, 1, 40, 1, 23, 10, 4…
$ independentObservations <int> 18, 1, 2, 12, 2, 13, 1, 17, 1, 18, 7, 4,…
$ totalIndividuals <dbl> 1, 1, 1, 1, 2, 5, 1, 3, 1, 1, 2, 1, 1, 2…# Notes:
# - Numeric covariates are averaged across cameras in each hexagon.
# - Categorical covariates use MODE aggregation.
# - Observation table gains fields like:
# totalIndividuals
# numberDeploymentsActiveAtDate
# which support occupancy/abundance modelling.
# 6. Link each species with its correct spatial scale
sp_scales <- data.frame(
scientificName = traits$binomial_verified,
home_range_m2 = traits$home_range_m2
)
# Add a friendly label: "1km2", "6km2", etc.
sp_scales$scale_name <- paste0(sp_scales$home_range_m2 / 1e6, "km2")
sp_scales scientificName home_range_m2 scale_name
1 Canis dingo 6e+06 6km2
2 Felis catus 6e+06 6km2
3 Orthonyx spaldingii 1e+06 1km2
4 Varanus varius 1e+06 1km21.3.7 Detection matrix
Step 5: Prepare matrices
For each species (i.e., in a for-loop):
Select the right spatial resampling scale based on home range data previously collected from the
traitdataR package.The spatial resampling function will add the spatial scale to the sampling unit name to reflect the resampled scale. Therefore, to work across multiple scales, one must standardise sampling unit names to something simple like
cellID.Additional simple covariates can be derived from more complex covaraites that have many levels. For example,
featureTypecontains several enumerated classes, but can be simply reduced to a two-level variable of on or off-trails based on the enumerated values types. Including fixed effect covaraites with fewer levels often improves modelling performance.WildObs calculates many site-level covariates across multiple spatial scales, including point values for the individual deployment coordinates, and in circular buffers around camera deployments covering areas of 1, 3, 5, and 10 km2. Unless you are particularly interested in how the same variable may affect wildlife occupancy across different spatial scales, one should thin the site covariates to the spatial scale that most closely matches the spatial resampling and home range scale. This is also a useful time to think critically about the covariates included in the analysis, since the analysis will be simplified by only selecting site-level covariates that will be useful for testing hypotheses or determining a best fitting model.
After site-level covariates are selected, select observation covariates from the spatialy resampled observations (e.g.,
numberDeploymentsActiveAtDate,trailStatus, etc.). These covariates will vary through time and per detection. Therefore, these covariates must be found in the observations, not covariates, table.Determine the structure of the detection history matrices you will create:
First, you must determine the maximum duration of the matrix (i.e., number of columns), and its recommended to not exceed 100 days to satisfy the population closure assumption of the model.
Next, you must determine the sampling window duration which is the number of days that fit into one column in the detection history matrix. Larger intervals (e.g., 7-10 days) are typically better for rare species with very low detections, while shorter values (e.g., 2-5 days) are better for frequently detected species.
- The goal here is to increase detection probability to enhance model performance.
Finally, determine if you want to use all sampling units in the resampled data, or only locationNames (i.e., large landscapes such as a national park) where the species was detected.
- Limiting the data to locationNames where the species was detected will improve model performance since the model will estimate non-zero occupancy for all sampling units even if we know the species is absent from a particular landscape. However, the species may be present but have very low detection probability, so it may be worth including locationNames with zero detections if there is strong rationale for inclusion.
Put together, the information you had just collated into the
WildObsR::matrix_generator()function. This function produces detection history matrices for multiple species and multiple resampling scales and ensures that the site-level and observation-level covaraites are properly aligned to facilitate an occupancy analysis.- The
WildObsR::matrix_generator()function contains an additional paramater calledtype, where you can specify if you want to create a detection history matrix (using detection-non-detection data) for occupancy modelling or a count history matrix (using count data) for abundance modelling. Abundance modelling is beyond the scope of this tutorial, so we will settype == "occupancy".
- The
Step 6: Build modelling objects
For occupancy models: extract the detection history matrix, site-level and observation-level covariates form the
WildObsR::matrix_generator()function and save them as anunmarked::unmarkedFrameOccu(UMF). This is a particular data structure formatted to work with occupancy models in the unmarked R package, thus facilitating easy analysis.For multiple species, you can store each UMF in a list to save space in your global environment. Can format the list as one UMF per species with the name of the species saved in the name of the element in the list.
# Required arguments (defined once)
dur <- 50 # maximum sampling duration
w <- 5 # sampling window duration
all_locationNames <- FALSE # only include locationNames where species were detected
# Build species + scale table
stopifnot(
exists("traits"),
all(c("binomial_verified", "home_range_m2") %in% names(traits))
)
sp_scales <- traits %>%
dplyr::select(scientificName = binomial_verified, home_range_m2) %>%
dplyr::mutate(
scale_name = paste0(home_range_m2 / 1e6, "km2")
)
## storage objects
vars_only <- list()
errors <- list()
# Loop over species
for (i in seq_len(nrow(sp_scales))) {
sp <- sp_scales$scientificName[i]
scale <- sp_scales$scale_name[i]
key <- paste0("cellID_", scale)
tryCatch({
# Extract resampled data for this scale
resamp_obs <- resampled_data$spatially_resampled_observations[[key]]
resamp_covs <- resampled_data$spatially_resampled_covariates[[key]]
if (is.null(resamp_obs) || is.null(resamp_covs)) {
stop(paste("Scale", scale, "not available for species", sp))
}
## Standardise cellID name
names(resamp_obs)[grepl("cellID", names(resamp_obs))] <- "cellID"
names(resamp_covs)[grepl("cellID", names(resamp_covs))] <- "cellID"
# Observation covariates: trail / off-trail
resamp_obs$trailStatus <- ifelse(
grepl("road|trail", resamp_obs$featureType, ignore.case = TRUE),
"onTrail", "offTrail"
)
# Choose covariates at closest spatial scale
target_scale <- suppressWarnings(as.numeric(gsub("km2", "", scale)))
if (is.na(target_scale)) target_scale <- 0
km2_cols <- names(resamp_covs)[stringr::str_detect(names(resamp_covs),
"_\\d+km2$|_point$")]
scale_info <- tibble::tibble(col = km2_cols) %>%
mutate(
scale_val = ifelse(grepl("_point$", col),
0,
as.numeric(stringr::str_extract(col, "\\d+(?=km2$)"))),
base = stringr::str_remove(col, "_(point|\\d+km2)$")
)
closest_cols <- scale_info %>%
group_by(base) %>%
slice_min(abs(scale_val - target_scale), n = 1, with_ties = FALSE) %>%
ungroup()
# Tag + mode columns
tag_cols <- intersect(c("bait", "predatorManagement"), names(resamp_covs))
mode_cols <- names(resamp_covs)[grepl("^mode_", names(resamp_covs))]
site_covs_keep <- unique(c(
tag_cols,
closest_cols$col,
"deploymentGroups",
"locationName"
))
obs_covs_keep <- unique(c(
"numberDeploymentsActiveAtDate",
"trailStatus",
mode_cols
))
## ensure landscapes are removed if NOT warning to be included in matrix
if(!all_locationNames){
# grab deployments w/ detections
sp_deps = resamp_obs$cellID[which(resamp_obs$scientificName == sp)]
# and grab the corresponding landscapes
sp_land = unique(resamp_covs$locationName[resamp_covs$cellID %in% sp_deps])
# thin covs to only those landsacpes
resamp_covs = resamp_covs[resamp_covs$locationName %in% sp_land, ]
# and thin observatiosn to match
resamp_obs = resamp_obs[resamp_obs$cellID %in% resamp_covs$cellID, ]
} # end locationName thinning conditon
# Run matrix generator (extraction only)
mat <- matrix_generator(
obs = resamp_obs, covs = resamp_covs,
dur = dur, w = w,
site_covs = site_covs_keep,
obs_covs = obs_covs_keep,
all_locationNames = all_locationNames,
scientificNames = sp,
type = "occupancy",
individuals = "max" # doesn't matter for occupancy, only abundance
)
# Save extracted pieces
vars_only[[sp]] <- list(
detection_matrix = mat[[1]]$detection_matrix,
site_covariates = mat[[1]]$site_level_covariates,
obs_covariates = mat[[1]]$observation_level_covariates
)
}, error = function(e) {
## Store error for review
errors[[sp]] <<- conditionMessage(e)
})
} # end loop Warning in matrix_generator(obs = resamp_obs, covs = resamp_covs, dur = dur, :
There was no variation in the site-level covariate: predatorManagement so it
has been removed from the matrix generation function.Warning in matrix_generator(obs = resamp_obs, covs = resamp_covs, dur = dur, :
There was no variation in the observation-level covariate: mode_source &
mode_IBRAsubRegionName for the species: Canis dingo so it has been removed from
the matrix generation function for this species.Warning in matrix_generator(obs = resamp_obs, covs = resamp_covs, dur = dur, :
There was no variation in the site-level covariate: predatorManagement so it
has been removed from the matrix generation function.Warning in matrix_generator(obs = resamp_obs, covs = resamp_covs, dur = dur, :
There was no variation in the observation-level covariate: mode_source &
mode_IBRAsubRegionName for the species: Felis catus so it has been removed from
the matrix generation function for this species.Warning in matrix_generator(obs = resamp_obs, covs = resamp_covs, dur = dur, :
There was no variation in the site-level covariate: predatorManagement so it
has been removed from the matrix generation function.Warning in matrix_generator(obs = resamp_obs, covs = resamp_covs, dur = dur, :
There was no variation in the observation-level covariate: mode_source &
mode_IBRAsubRegionName for the species: Orthonyx spaldingii so it has been
removed from the matrix generation function for this species.Warning in matrix_generator(obs = resamp_obs, covs = resamp_covs, dur = dur, :
There was no variation in the site-level covariate: predatorManagement so it
has been removed from the matrix generation function.Warning in matrix_generator(obs = resamp_obs, covs = resamp_covs, dur = dur, :
There was no variation in the observation-level covariate: mode_source &
mode_IBRAsubRegionName for the species: Varanus varius so it has been removed
from the matrix generation function for this species.You can see there are two repeating warnings for all the four species:
Warning 1: “There was no variation in the site-level covariate: bait & predatorManagement”
Warning 2: “There was no variation in the observation-level covariate: mode_source & mode_IBRAsubRegionName”
For warning 1, since all the camera deployments had bait = “none”, and had predatorManagement = “No management”, so they are two constant variable have no modelling values, so WildObsR automatically drops it. This is good for us.
For warning 2, similar to warning 1, all observations came from the same data provider (source) and all observations were in the same IBRAsubRegionName after resampling, again, no variation, they can’t be used as covariates, so WildObsR automatically drops them.
# Summary of what succeeded / failed
names(vars_only)[1] "Canis dingo" "Felis catus" "Orthonyx spaldingii"
[4] "Varanus varius" errorslist()We see four species:
"Canis dingo" "Felis catus" "Orthonyx spaldingii" "Varanus varius"This means:
- the resampling worked
- the matrix generator worked
- did not lose any species
Also, we see the empty
list()which means
There were no failures
Every species successfully produced data
No missing scale issues
No resampling errors
No deployment group issues blocking the code
1.4 Occupancy model with WildObs data
1.4.1 Prepare UMF
First, we need to generate an UMF for each of the species we select.
# Extract UMFs per species, using the values gathered from the matrix_generator() function
# Repeat per species
umf_list = list()
for(i in 1:length(vars_only)){
## select data from one species
dat = vars_only[[i]]
## and store in UMF object
umf = unmarked::unmarkedFrameOccu(y = dat$detection_matrix,
siteCovs = dat$site_covariates,
obsCovs = dat$obs_covariates)
# save in the list
umf_list[[i]] = umf
names(umf_list)[i] = names(vars_only)[i]
} # end per species Warning: siteCovs contains characters. Converting them to factors.Warning: obsCovs contains characters. Converting them to factors.Warning: siteCovs contains characters. Converting them to factors.Warning: obsCovs contains characters. Converting them to factors.Warning: siteCovs contains characters. Converting them to factors.Warning: obsCovs contains characters. Converting them to factors.Warning: siteCovs contains characters. Converting them to factors.Warning: obsCovs contains characters. Converting them to factors.rm(i, dat, umf)The warnings you see are a normal part of the modelling process. They occur when a categorical variable needs to be converted into a model-ready format. The system handles this automatically to keep the models reliable.
## inspect results
names(umf_list) # all species present[1] "Canis dingo" "Felis catus" "Orthonyx spaldingii"
[4] "Varanus varius" # select which species we will analyze
# sp_occu = "Canis dingo"
# sp_occu = "Varanus varius"
sp_occu = "Felis catus"
# sp_occu = "Orthonyx spaldingii"We successfully made the occupancy umf for each species. Lets inspect the umf object for a single species, Felis catus.
# select one umf
umf = umf_list[[sp_occu]]
# inspect data
summary(umf)unmarkedFrame Object
94 sites
Maximum number of observations per site: 10
Mean number of observations per site: 9.81
Sites with at least one detection: 30
Tabulation of y observations:
0 1 <NA>
835 87 18
Site-level covariates:
cellID predatorManagement
Daintree_NP_108_cellID_6km2_2022_Z_Amir: 1 No management:94
Daintree_NP_109_cellID_6km2_2022_Z_Amir: 1
Daintree_NP_123_cellID_6km2_2022_Z_Amir: 1
Daintree_NP_124_cellID_6km2_2022_Z_Amir: 1
Daintree_NP_125_cellID_6km2_2022_Z_Amir: 1
Daintree_NP_134_cellID_6km2_2022_Z_Amir: 1
(Other) :88
polygon_6km2 deploymentGroups
Daintree_NP_108_cellID_6km2: 1 Daintree_NP_2022_Amir :23
Daintree_NP_109_cellID_6km2: 1 Danbulla_NP_2022_Amir :18
Daintree_NP_123_cellID_6km2: 1 Eacham_Curtain_Fig_NPs_2022_Amir: 9
Daintree_NP_124_cellID_6km2: 1 Mount_Lewis_NP_2022_Amir :18
Daintree_NP_125_cellID_6km2: 1 Wooroonooran_NP_2022_Amir :26
Daintree_NP_134_cellID_6km2: 1
(Other) :88
locationName samplingStart
Daintree_NP :23 Min. :2022-09-20 10:31:04
Danbulla_NP :18 1st Qu.:2022-09-27 19:43:48
Eacham_Curtain_Fig_NPs: 9 Median :2022-10-04 23:55:10
Mount_Lewis_NP :18 Mean :2022-10-30 03:15:30
Wooroonooran_NP :26 3rd Qu.:2022-12-20 12:50:41
Max. :2022-12-28 15:22:24
samplingEnd Avg_FLII_5km2
Min. :2022-10-27 22:23:21 Min. :-2.923473
1st Qu.:2022-12-07 09:12:28 1st Qu.:-0.008334
Median :2022-12-11 12:07:39 Median : 0.185240
Mean :2023-01-09 11:19:24 Mean : 0.000000
3rd Qu.:2023-03-06 13:15:16 3rd Qu.: 0.603011
Max. :2023-03-19 14:20:44 Max. : 1.013625
Avg_GEEBAM_fire_severity_2020_5km2 Avg_HCAS_static_5km2 Avg_NDVI_5km2
Min. :-0.139 Min. :-2.8119 Min. :-2.9234
1st Qu.:-0.139 1st Qu.:-0.5950 1st Qu.:-0.5191
Median :-0.139 Median : 0.4492 Median : 0.5358
Mean : 0.000 Mean : 0.0000 Mean : 0.0000
3rd Qu.:-0.139 3rd Qu.: 0.7509 3rd Qu.: 0.7888
Max. : 8.570 Max. : 1.0075 Max. : 0.8586
Avg_altitude_5km2 Avg_ecoregion_intactness_5km2 Avg_human_footprint_5km2
Min. :-1.6687 Min. :-1.4897 Min. :-1.2595
1st Qu.:-0.6907 1st Qu.:-0.8677 1st Qu.:-0.6122
Median : 0.2200 Median :-0.1543 Median :-0.2885
Mean : 0.0000 Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.8173 3rd Qu.: 0.4154 3rd Qu.: 0.5206
Max. : 1.5877 Max. : 2.3479 Max. : 3.8219
Avg_human_population_density_5km2 Avg_mean_monthly_precipitation_5km2
Min. :-0.5067 Min. :-1.0991
1st Qu.:-0.5067 1st Qu.:-0.8878
Median :-0.5067 Median :-0.2155
Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.1407 3rd Qu.: 1.2302
Max. : 4.3605 Max. : 1.8361
Avg_mean_monthly_temperature_5km2 Avg_nighttime_lights_5km2
Min. :-2.2986 Min. :-0.92779
1st Qu.:-0.6442 1st Qu.:-0.44566
Median : 0.0666 Median :-0.19116
Mean : 0.0000 Mean : 0.00000
3rd Qu.: 0.8914 3rd Qu.: 0.06971
Max. : 1.4103 Max. : 6.98644
Avg_protected_areas_5km2 Avg_standardized_precipitation_index_5km2
Min. :-3.3449 Min. :-1.4053
1st Qu.:-0.7098 1st Qu.:-0.7020
Median : 0.5792 Median :-0.2626
Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.7754 3rd Qu.: 1.2971
Max. : 0.7754 Max. : 1.7821
Avg_terrain_ruggedness_index_5km2
Min. :-1.7757286
1st Qu.:-0.8827803
Median :-0.0007964
Mean : 0.0000000
3rd Qu.: 0.7947049
Max. : 3.1225449
Observation-level covariates:
trailStatus numberDeploymentsActiveAtDate
offTrail : 20 Min. : 0.0
offTrail - onTrail:818 1st Qu.: 6.0
onTrail : 84 Median :10.0
NA's : 18 Mean :10.4
3rd Qu.:12.0
Max. :43.0 # visualize
plot(umf)
This heatmap shows detections across sites (rows) and repeated observation periods (columns). Most sites have many non-detections (light cells), with detections occurring sporadically, which is typical for wildlife monitoring data, especially for rare species. A small number of sites show repeated detections across multiple observations, indicating higher or more consistent activity at those locations.
1.4.2 Null model for Occupancy model
Creating occupancy models using the unmarked R package follows a similar syntax to writing linear models in R. We will use the unmarked::occu() function to create occupancy models. The formula is specifid as a double sided formula describing detection probability first (left side) and then occupancy (right side), where tildas (~) denote each formula. Before we begin adding covariates to our occupancy models, its wise to generate a null model that uses no covariates in either formula as the basis of comparison.
####### Basic hand-written cat occupancy models & visualization
# create a null model w/ no variables on the detection (left) or occupancy (right) formula
mod1 <- unmarked::occu(~1 ~1, data = umf)
out <- capture.output({
cat("=== Null occupancy model ===\n")
print(summary(mod1))
cat("\nAIC:", mod1@AIC)
})
cat(out, sep = "\n")=== Null occupancy model ===
Call:
unmarked::occu(formula = ~1 ~ 1, data = umf)
Occupancy (logit-scale):
Estimate SE z P(>|z|)
-0.708 0.226 -3.14 0.0017
Detection (logit-scale):
Estimate SE z P(>|z|)
-0.881 0.138 -6.4 1.52e-10
AIC: 472.0165
Number of sites: 94
$state
Estimate SE z P(>|z|)
(Intercept) -0.7083094 0.225706 -3.138195 0.001699917
$det
Estimate SE z P(>|z|)
(Intercept) -0.8808233 0.1375567 -6.403346 1.52008e-10
AIC: 472.0165This null occupancy model estimates that Felis catus occupy about X% of sites, with a per-occasion detection probability of roughly Y%, indicating imperfect detection. The low detection probability explains why many occupied sites have few or no detections. This model provides a baseline against which more complex models with detection and environmental covariates can be compared.
1.4.3 Detection models with alternative detection covariates
## Detection models with alternative detection covariates
## Goal: identify the best-supported detection structure before modelling occupancy
# Detection varies with sampling effort only
det1 <- unmarked::occu(~ numberDeploymentsActiveAtDate ~ 1, data = umf)
# Detection varies with camera placement (on/off trail)
det2 <- unmarked::occu(~ trailStatus ~ 1, data = umf)
# Detection varies with both trail placement and sampling effort
det3 <- unmarked::occu(~ trailStatus + numberDeploymentsActiveAtDate ~ 1, data = umf)
## Compare AIC values across detection models
aic_det <- data.frame(
model = c("effort only", "trail status", "trail + effort"),
AIC = c(det1@AIC, det2@AIC, det3@AIC)
)
aic_det model AIC
1 effort only 462.9409
2 trail status 462.0726
3 trail + effort 450.4781These results show that detection probability is strongly influenced by trail placement & sampling effort, and combining trail status with sampling effort provides a substantially better fit than either variable alone.
The trail + effort model has the lowest AIC (ΔAIC > 8 compared to the others), indicating strong support for using both covariates in the detection component of the occupancy model.
1.4.4 Select state variables
The WildObsR::matrix_generator() function has already standardized numeric covariates to have a mean of zero and a standard deviation of 1 to ensure comparable model outputs. Before feeding the resampled covariates into the function, we also limited to our spatial scale of interest to match the home-range size of our species.
# these are our options to include
summary(umf@siteCovs) cellID predatorManagement
Daintree_NP_108_cellID_6km2_2022_Z_Amir: 1 No management:94
Daintree_NP_109_cellID_6km2_2022_Z_Amir: 1
Daintree_NP_123_cellID_6km2_2022_Z_Amir: 1
Daintree_NP_124_cellID_6km2_2022_Z_Amir: 1
Daintree_NP_125_cellID_6km2_2022_Z_Amir: 1
Daintree_NP_134_cellID_6km2_2022_Z_Amir: 1
(Other) :88
polygon_6km2 deploymentGroups
Daintree_NP_108_cellID_6km2: 1 Daintree_NP_2022_Amir :23
Daintree_NP_109_cellID_6km2: 1 Danbulla_NP_2022_Amir :18
Daintree_NP_123_cellID_6km2: 1 Eacham_Curtain_Fig_NPs_2022_Amir: 9
Daintree_NP_124_cellID_6km2: 1 Mount_Lewis_NP_2022_Amir :18
Daintree_NP_125_cellID_6km2: 1 Wooroonooran_NP_2022_Amir :26
Daintree_NP_134_cellID_6km2: 1
(Other) :88
locationName samplingStart
Daintree_NP :23 Min. :2022-09-20 10:31:04
Danbulla_NP :18 1st Qu.:2022-09-27 19:43:48
Eacham_Curtain_Fig_NPs: 9 Median :2022-10-04 23:55:10
Mount_Lewis_NP :18 Mean :2022-10-30 03:15:30
Wooroonooran_NP :26 3rd Qu.:2022-12-20 12:50:41
Max. :2022-12-28 15:22:24
samplingEnd Avg_FLII_5km2
Min. :2022-10-27 22:23:21 Min. :-2.923473
1st Qu.:2022-12-07 09:12:28 1st Qu.:-0.008334
Median :2022-12-11 12:07:39 Median : 0.185240
Mean :2023-01-09 11:19:24 Mean : 0.000000
3rd Qu.:2023-03-06 13:15:16 3rd Qu.: 0.603011
Max. :2023-03-19 14:20:44 Max. : 1.013625
Avg_GEEBAM_fire_severity_2020_5km2 Avg_HCAS_static_5km2 Avg_NDVI_5km2
Min. :-0.139 Min. :-2.8119 Min. :-2.9234
1st Qu.:-0.139 1st Qu.:-0.5950 1st Qu.:-0.5191
Median :-0.139 Median : 0.4492 Median : 0.5358
Mean : 0.000 Mean : 0.0000 Mean : 0.0000
3rd Qu.:-0.139 3rd Qu.: 0.7509 3rd Qu.: 0.7888
Max. : 8.570 Max. : 1.0075 Max. : 0.8586
Avg_altitude_5km2 Avg_ecoregion_intactness_5km2 Avg_human_footprint_5km2
Min. :-1.6687 Min. :-1.4897 Min. :-1.2595
1st Qu.:-0.6907 1st Qu.:-0.8677 1st Qu.:-0.6122
Median : 0.2200 Median :-0.1543 Median :-0.2885
Mean : 0.0000 Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.8173 3rd Qu.: 0.4154 3rd Qu.: 0.5206
Max. : 1.5877 Max. : 2.3479 Max. : 3.8219
Avg_human_population_density_5km2 Avg_mean_monthly_precipitation_5km2
Min. :-0.5067 Min. :-1.0991
1st Qu.:-0.5067 1st Qu.:-0.8878
Median :-0.5067 Median :-0.2155
Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.1407 3rd Qu.: 1.2302
Max. : 4.3605 Max. : 1.8361
Avg_mean_monthly_temperature_5km2 Avg_nighttime_lights_5km2
Min. :-2.2986 Min. :-0.92779
1st Qu.:-0.6442 1st Qu.:-0.44566
Median : 0.0666 Median :-0.19116
Mean : 0.0000 Mean : 0.00000
3rd Qu.: 0.8914 3rd Qu.: 0.06971
Max. : 1.4103 Max. : 6.98644
Avg_protected_areas_5km2 Avg_standardized_precipitation_index_5km2
Min. :-3.3449 Min. :-1.4053
1st Qu.:-0.7098 1st Qu.:-0.7020
Median : 0.5792 Median :-0.2626
Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.7754 3rd Qu.: 1.2971
Max. : 0.7754 Max. : 1.7821
Avg_terrain_ruggedness_index_5km2
Min. :-1.7757286
1st Qu.:-0.8827803
Median :-0.0007964
Mean : 0.0000000
3rd Qu.: 0.7947049
Max. : 3.1225449
1.4.5 Compare alternative random‐effect structures for the state (occupancy) process
We can include random-intercept effects in both the occupancy and deteciton formula of occupancy models to account for variation that we are not necessarily interested in. For example, we may care about how a species occupancy varies along an elevation gradient, but are less interested in how it varies per landscape. However, we are aware there could be unmeasured variation between landscapes that should be accounted for in our modelling process.
## Detection structure is held constant (trailStatus + sampling effort)
## Compare alternative random‐effect structures for the state model
state_re1 <- unmarked::occu(
~ trailStatus + numberDeploymentsActiveAtDate
~ (1 | deploymentGroups),
data = umf
)
state_re2 <- unmarked::occu(
~ trailStatus + numberDeploymentsActiveAtDate
~ (1 | locationName),
data = umf
)
cat(
"\n Random effects comparison (lower AIC = better):\n",
"------------------------------------------------\n",
"Random intercept: deploymentGroups | AIC =", round(state_re1@AIC, 2), "\n",
"Random intercept: locationName | AIC =", round(state_re2@AIC, 2), "\n"
)
Random effects comparison (lower AIC = better):
------------------------------------------------
Random intercept: deploymentGroups | AIC = 443.33
Random intercept: locationName | AIC = 443.33 Both random‐effects structures (deploymentGroups and locationName) produce identical AIC values (443.18), indicating no difference in model support between the two grouping factors. In this case, either random effect is statistically equivalent, and the choice should be guided by study design and interpretability rather than model fit.
We therefore used a random intercept for locationName, as cameras within the same location are likely to share common ecological context (e.g. habitat, management history, and accessibility). This is because each landscape only contained one deploymentGroup, but when combining multiple datasets together, this could vary substantially!
1.4.6 Hypothesis-driven occupancy models
## Detection formula is fixed based on earlier AIC comparison:
## ~ trailStatus + numberDeploymentsActiveAtDate
## Random effect is fixed at locationName
## Each model tests ONE ecological hypothesis
## gather all variables in a vector
occ_vars = c("Avg_HCAS_static_5km2", "Avg_human_population_density_5km2",
"Avg_NDVI_5km2", "Avg_FLII_5km2", "Avg_altitude_5km2")
## H1: HCAS
## Hypothesis: species occupancy decreases with increasing HCAS
h1 <- unmarked::occu(
~ trailStatus + numberDeploymentsActiveAtDate # detection model
~ (1 | locationName) + Avg_HCAS_static_5km2, # state (occupancy) model
data = umf
)
## H2: Human population density
## Hypothesis: species occupancy increases with human population density
h2 <- unmarked::occu(
~ trailStatus + numberDeploymentsActiveAtDate # detection model
~ (1 | locationName) +
Avg_human_population_density_5km2, # state model
data = umf
)
## H3: NDVI
## Hypothesis: species occupancy decreases with increasing vegetation greenness
h3 <- unmarked::occu(
~ trailStatus + numberDeploymentsActiveAtDate # detection model
~ (1 | locationName) + Avg_NDVI_5km2, # state model
data = umf
)
## H4: Forest Landscape Integrity Index (FLII)
## Hypothesis: species occupancy increases with higher forest integrity
h4 <- unmarked::occu(
~ trailStatus + numberDeploymentsActiveAtDate # detection model
~ (1 | locationName) + Avg_FLII_5km2, # state model
data = umf
)
## H5: altiide
## Hypothesis: species occupancy increases with higher altitude
h5 <- unmarked::occu(
~ trailStatus + numberDeploymentsActiveAtDate # detection model
~ (1 | locationName) + Avg_altitude_5km2, # state model
data = umf
)## Summarise model support using AIC
## Lower AIC = stronger support
## Create a compact comparison table
hypotheses <- data.frame(
Hypothesis = c(
"HCAS (expected negative)",
"Human population density (expected positive)",
"NDVI (expected negative)",
"Forest integrity – FLII (expected positive)",
"Altitude (expected positive)"
),
AIC = c(
h1@AIC, # AIC for HCAS model
h2@AIC, # AIC for human population model
h3@AIC, # AIC for NDVI model
h4@AIC, # AIC for FLII model
h5@AIC # AIC for elev model
)
)
## Order models from best to worst support
hypotheses[order(hypotheses$AIC), ] Hypothesis AIC
3 NDVI (expected negative) 442.0625
2 Human population density (expected positive) 445.0524
1 HCAS (expected negative) 445.1330
5 Altitude (expected positive) 445.2381
4 Forest integrity – FLII (expected positive) 448.0915All five habitat hypotheses have similar AIC values (ΔAIC < 4), indicating no strong evidence that any single covariate clearly outperforms the others in explaining Felis catus occupancy at this scale. NDVI has the lowest AIC and is therefore marginally best supported, but the difference is too small to claim a meaningful advantage. Practically, this suggests that Felis catus occupancy is weakly influenced by multiple correlated landscape features rather than driven by one dominant variable, and model choice should be guided by ecological plausibility and parsimony, not AIC alone.
## before creating multi-variate models, ensure covariates are NOT correlated!
## grab the relevant variables
var_dat = umf@siteCovs[, occ_vars]
## compute a correlation matrix
cor_mat = cor(var_dat, use = "complete.obs")
## determine a threshold
thresh <- 0.7
# get upper triangle only (avoid duplicates + diagonal)
high_cor <- which(abs(cor_mat) >= thresh &
upper.tri(cor_mat),
arr.ind = TRUE)
# return variable names + correlation values
data.frame(
var1 = rownames(cor_mat)[high_cor[,1]],
var2 = colnames(cor_mat)[high_cor[,2]],
correlation = cor_mat[high_cor]
) var1 var2 correlation
1 Avg_HCAS_static_5km2 Avg_NDVI_5km2 0.8037638
2 Avg_HCAS_static_5km2 Avg_FLII_5km2 0.7880809
3 Avg_NDVI_5km2 Avg_FLII_5km2 0.7143303Before creating multi-variate models, its important to ensure that covariates are not strongly correlated with each other. In this case, we are using a cutoff of 0.7 to ensure we include covariates that are clearly distinguishable from each other. In the print out above, we can see that HCAS is strongly correlated with NDVI and FLII, which are also strongly correlated with each other. Therefore, we would not include these variables together in the same multi-variate model.
## Multi-variate state model: forest integrity + human pressure
## Tests whether combining NDVI and human population density improves
## explanatory power beyond single-covariate models
multi1 <- unmarked::occu(
~ trailStatus + numberDeploymentsActiveAtDate # detection process
~ (1 | locationName) # spatial random effect
+ Avg_NDVI_5km2 # forest integrity
+ Avg_human_population_density_5km2, # human pressure
data = umf
)
summary(multi1)
Call:
unmarked::occu(formula = ~trailStatus + numberDeploymentsActiveAtDate ~
(1 | locationName) + Avg_NDVI_5km2 + Avg_human_population_density_5km2,
data = umf)
Occupancy (logit-scale):
Random effects:
Groups Name Variance Std.Dev.
locationName (Intercept) 0.806 0.898
Fixed effects:
Estimate SE z P(>|z|)
(Intercept) -0.85612 0.528 -1.62096 0.1050
Avg_NDVI_5km2 0.86767 0.516 1.68202 0.0926
Avg_human_population_density_5km2 -0.00354 0.375 -0.00946 0.9925
Detection (logit-scale):
Estimate SE z P(>|z|)
(Intercept) -9.8745 39.567 -0.250 0.802926
trailStatusoffTrail - onTrail 7.7249 39.568 0.195 0.845210
trailStatusonTrail 9.5280 39.569 0.241 0.809715
numberDeploymentsActiveAtDate 0.0788 0.022 3.580 0.000344
AIC: 444.058
Number of sites: 94multi1@AIC # AIC is worse than the NDVI-only model,[1] 444.058 # indicating worse additional support for the combined model
## try combining NDVI and altitude
multi2 <- unmarked::occu(
~ trailStatus + numberDeploymentsActiveAtDate # detection process
~ (1 | locationName) # spatial random effect
+ Avg_NDVI_5km2 # forest integrity
+ Avg_altitude_5km2, # elevatoion
data = umf
)
summary(multi2)
Call:
unmarked::occu(formula = ~trailStatus + numberDeploymentsActiveAtDate ~
(1 | locationName) + Avg_NDVI_5km2 + Avg_altitude_5km2, data = umf)
Occupancy (logit-scale):
Random effects:
Groups Name Variance Std.Dev.
locationName (Intercept) 0.756 0.869
Fixed effects:
Estimate SE z P(>|z|)
(Intercept) -0.854 0.518 -1.649 0.0992
Avg_NDVI_5km2 1.016 0.538 1.887 0.0591
Avg_altitude_5km2 -0.348 0.455 -0.764 0.4451
Detection (logit-scale):
Estimate SE z P(>|z|)
(Intercept) -9.3295 30.755 -0.303 0.761621
trailStatusoffTrail - onTrail 7.1836 30.755 0.234 0.815314
trailStatusonTrail 8.9848 30.757 0.292 0.770195
numberDeploymentsActiveAtDate 0.0785 0.022 3.571 0.000355
AIC: 443.4736
Number of sites: 94multi2@AIC # AIC is a tad better than the NDVI-only model,[1] 443.4736The unmarked R package has a number of useful tools for ranking competing models. We will use the unmarked::fitList() function to organize models for model selection, ensuring we specify which is the null model and point of comparison. Then we will use the unmarked::modSel() function create a table containing all model parameter effect sizes and AIC scores to enable an easy comparison across all models.
## Model comparison using AIC
## Combine all candidate models (detection, random effects, habitat hypotheses)
mods <- fitList(
# null model first
"null" = mod1,
# Detection structure
"effort" = det1,
"trails" = det2,
"trails_and_effort" = det3,
# Random-effect structures
"location_RE" = state_re2,
# State (occupancy) hypotheses
"HCAS" = h1,
"human" = h2,
"ndvi" = h3,
"flii" = h4,
"ndvi_and_human" = multi1,
"ndvi_and_elev" = multi2
)
## Rank models by AIC
mod_select <- modSel(mods)@FullWarning in sqrt(diag(vcov(x, altNames = TRUE))): NaNs produced## Inspect key AIC results
mod_select[, c("model", "nPars", "AIC", "delta", "cumltvWt")] model nPars AIC delta cumltvWt
8 ndvi 6 442.0625 0.000000 0.3451315
5 location_RE 5 443.3278 1.265275 0.5284615
11 ndvi_and_elev 7 443.4736 1.411050 0.6989044
10 ndvi_and_human 7 444.0580 1.995456 0.8261599
7 human 6 445.0524 2.989883 0.9035597
6 HCAS 6 445.1330 3.070463 0.9779030
9 flii 6 448.0915 6.028991 0.9948388
4 trails_and_effort 5 450.4781 8.415526 0.9999742
3 trails 4 462.0726 20.010018 0.9999898
2 effort 3 462.9409 20.878356 0.9999999
1 null 2 472.0165 29.953967 1.0000000NDVI is the top‐ranked model, with the multivariate model combining NDVI and human population density performing almost as well (ΔAIC < 1), indicating that both vegetation greenness and overall human population centers are strongly supported predictors of Felis catus occupancy. Models including HCAS and those differing only by random‐effect structure receive some support (ΔAIC ≈ 1) but are clearly less informative than NDVI or human population density. HCAS adds little explanatory power (ΔAIC > 2), but does not improve model fit. In contrast, detection‐only models based on effort or trail use perform very poorly (ΔAIC ≫ 8), confirming that Felis catus occupancy in this system is driven primarily by landscape vegetation condition rather than detectability alone.
### Generate prediction data for key habitat covariates ----
# Create a sequence of human population values across the observed range
newd_human <- data.frame(
Avg_human_population_density_5km2 = seq(
from = min(umf@siteCovs$Avg_human_population_density_5km2),
to = max(umf@siteCovs$Avg_human_population_density_5km2),
length.out = 100
)
)
# Create a sequence of NDVI values across the observed range
newd_ndvi <- data.frame(
Avg_NDVI_5km2 = seq(
from = min(umf@siteCovs$Avg_NDVI_5km2),
to = max(umf@siteCovs$Avg_NDVI_5km2),
length.out = 100
)
)
### Predict occupancy across gradients ----
# Predict occupancy as a function of human
predict_human <- predict(
h2, # human state model
type = "state",
newdata = newd_human,
appendData = TRUE,
re.form = NA # average across random-effect levels
)
predict_human$key_var <- "human_pop"
names(predict_human)[5] <- "simulated_cov"
# Predict occupancy as a function of NDVI
predict_ndvi <- predict(
h3, # NDVI state model
type = "state",
newdata = newd_ndvi,
appendData = TRUE,
re.form = NA
)
predict_ndvi$key_var <- "NDVI"
names(predict_ndvi)[5] <- "simulated_cov"
### Combine predictions for plotting ----
predict_df <- rbind(predict_human, predict_ndvi)### Visualise predicted occupancy responses=
# human_pop response
ggplot(
predict_df[predict_df$key_var == "human_pop", ],
aes(x = simulated_cov, y = Predicted)
) +
geom_line(color = "steelblue", linewidth = 1.2) +
geom_ribbon(
aes(ymin = lower, ymax = upper),
fill = "steelblue",
alpha = 0.25
) +
coord_cartesian(ylim = c(0, 1)) +
theme_test() +
labs(
x = "Human populaiton density (standardised)",
y = "Predicted occupancy"
)
This plot shows a mildly negative relationship between human population density and predicted occupancy. As human population density increases, the probability of occupancy lowers steadily, though the confidence interval widens due to limited sampling in areas with many people. The shaded band indicates uncertainty around the prediction, which is wider at higher popualtion density values and narrows slightly as human population density decreases improves.
# NDVI response
ggplot(
predict_df[predict_df$key_var == "NDVI", ],
aes(x = simulated_cov, y = Predicted)
) +
geom_line(color = "darkgreen", linewidth = 1.2) +
geom_ribbon(
aes(ymin = lower, ymax = upper),
fill = "darkgreen",
alpha = 0.25
) +
coord_cartesian(ylim = c(0, 1)) +
theme_test() +
labs(
x = "Normalized Difference Vegetation Index (NDVI, standardised)",
y = "Predicted occupancy"
)
This plot shows a strong positive relationship between NDVI and predicted occupancy. Occupancy is very low in areas with low vegetation greenness and increases sharply as NDVI rises, indicating a preference for more productive or densely vegetated habitats. The shaded confidence band reflects uncertainty in the predictions, which is larger at lower NDVI values and narrows slightly at higher vegetation levels.
And, that’s pretty much it for the simple stuff!
if you made it this far, you may also be interested in how
we iterate this process for many species… but stay tuned for more!
References
Nakashima, Y. (2020). Potentiality and limitations of N‐mixture and Royle‐Nichols models to estimate animal abundance based on noninstantaneous point surveys. Population Ecology, 62(1), 151-157.
Amir, Z., Bruce, T., & Contributors. (2024). WildObsR: Professional tools for camera trap data access, management, and analysis in R. R package version 0.1.0. https://github.com/WildObs/WildObsR
Fiske, I., & Chandler, R. (2011). Unmarked: an R package for fitting hierarchical models of wildlife occurrence and abundance. Journal of statistical software, 43, 1-23.
Amir, Z., Moore, J. H., Negret, P. J., & Luskin, M. S. (2022). Megafauna extinctions produce idiosyncratic Anthropocene assemblages. Science Advances, 8(42), eabq2307.
Linkie, M. (2020). Managing threatened ungulates in logged-primary forest mosaics in Malaysia. PLoS One, 15(12), e0243932.
Anderson, S. E., Amir, Z., Bruce, T., & Luskin, M. S. (2025). Range‐Wide Camera Trapping for the Australian Cassowary Reveals Habitat Associations With Rainfall and Forest Quality. Ecology and Evolution, 15(6), e71464.
M. Rayan D., M. Linkie, Managing threatened ungulates in logged-primary forest mosaics in Malaysia. PLOS ONE 15, e0243932 (2020).

How to cite this Notebook
Zhao, X. Y., & Amir, Z. (2026). Single-Species Single-Season Occupancy Model - Practical (Version 1.0) [Computational notebook]. Zenodo. https://doi.org/10.5281/zenodo.19552244

